Private Sector Data for Performance Management
Final Report
July 2011
CHAPTER 4. QUALITY ASSURANCE AND VALIDATION
This section summarizes the findings of the third task of this project, which was intended to address various technical issues related to quality assurance and validation of private sector data. The quality of private sector data should be ensured, as performance data could be used for a number of critical policy and investment decisions. Based on the team's review of current practice, the private sector data quality levels vary widely among vendors, if it is even measured systematically. The I-95 Corridor Coalition has done the most extensive testing of real-time traffic speeds, and in the past two years the data provider has met the established data quality requirements in the contract. Several providers have extensive internal data quality processes but seldom make the results publicly available.
One of the most important considerations when considering data quality for performance measures is that most performance measures use historical averages for longer time intervals over multiple days, weeks, or months. Therefore, the error measured in real-time traffic data is not the same level as the error in an historical average. Over multiple days and time intervals, some of the random error in real-time data cancels out and results in a lower error magnitude for historical data. For a simple example, consider 2 days for a single time interval, and the first day the error is +5 mph and the second day the error is -5 mph. Therefore, the error in the historical average will be 0 mph. The implication of this principle is that historical averages will have at least the same but typically better quality levels than the corresponding raw real-time data. Therefore, if there are accuracy specifications for real-time traffic data (i.e., Section 1201), the historical averages from this real-time data typically will have better accuracy levels.
Quality Assurance Methods
There are at least three approaches to assess whether historical private sector data quality meets specified levels, and these basic approaches have already been used in several instances. The three approaches are outlined below and are ordered in terms of increasing cost and complexity.
Office-Based Statistical Analysis of Data And Metadata
This approach would be the least costly option but also the least definitive quality assessment. In this approach, statistical process control methods are used to identify those data that statistically deviate outside of expected properties. This approach can only be used to identify suspect data and does not result in a definitive and quantitative accuracy measure. This statistical process control approach is used by FHWA contractors in reviewing the quality of the Intelligent Transportation Infrastructure Program (ITIP) data.
Metadata that expressly serves as or can be interpreted as indicator of data quality can be used to gain an overall understanding as to how data quality has evolved over time, at least from data provider's perspective. Additionally, if it is possible to establish the correlation between the provided metadata and actual data quality then it will be possible to draw stronger conclusions on archived data quality that were not even directly validated. In this respect, it is crucial to have a close dialog with the data provider to verify the interpretation of their provided metadata and to factor in any changes that they might have incorporated to the production and target use of their provided quality indicators over time.
Compare To Other Trusted Public Sector Data Sources
This approach involves gathering existing public sector data of a known or trusted quality level and comparing to the private sector data. For example, the FHWA or its contractor could gather and use existing high-quality (e.g., toll tag-based or Bluetooth-based) travel time data from permanent traffic monitoring locations as a benchmark in several US cities (e.g., Houston, New York, San Francisco). Other cities may have fixed-point sensor systems with close enough spacing to permit a valid comparison. This method is more definitive than a statistical process control approach, but there are typically enough differences in road segmentation and/or measurement type (fixed point vs. link) to introduce some uncertainty. TTI has used this approach in several instances to assess the quality of historical average speed data.
Evaluate the Quality of Real-Time Data and Extrapolate to Historical Averages
This approach is the most costly on a nationwide basis but also the most definitive, especially if temporary/portable equipment (e.g., Bluetooth-based) provides large vehicle samples at high accuracy levels. In this approach, portable traffic monitoring equipment is deployed to numerous locations, collecting benchmark data for one or more weeks at each location. Quantitative accuracy levels are then computed by comparing the private sector data to the established benchmark data. This approach is used by the University of Maryland to assess the quality of real-time traveler information along the I-95 corridor in multiple states. As mentioned earlier, this approach would need to account for the principle that the random error in real-time data is typically reduced when computing historical averages.
In this approach real-time data collection should be representative of the overall data to be covered under the validation effort. In other words, the extent and distribution of validation-related data collection should be enough so that we can comfortably generalize the findings to the whole area and time frame for which data is being purchased. This issue is further discussed in the section on sampling procedure.
The second consideration in this case is that under ideal conditions the adopted data collection technology used in the validation should be superior to that of the vendor's. For instance, it does not make sense to use loop detector data to validate travel times obtained by drive tests. On the other hand, validation of travel time data produced by loop detector data based on data obtained by conducting drive tests makes sense. However, more than anything else, budgetary and technological considerations might play a decisive role on the extent and quality of the validation effort.
Drawing conclusions on the archived data quality can be accomplished by investigating the variations of data quality over its recent history. Based on such investigations, historic data quality can be extrapolated to the further past. Clearly, this is an indirect inference method that needs to be used cautiously. Generally speaking, extrapolations are more accurate when they are closer to the actual observations and lose their accuracy as we move further away from the actual observation points.
For instance, Figure 1 shows a schematic of the application of such method. In this Figure, it is assumed that archived data from 2007 has become available. In addition, ever since 2008, real-time validation of the data has been performed for three consecutive years which resulted in data quality measures indicated by solid dots. At the end of 2010, it would be possible to draw conclusions on the observed trend of the data quality measure(s) in consideration and to cautiously extrapolate into the past and to the future.
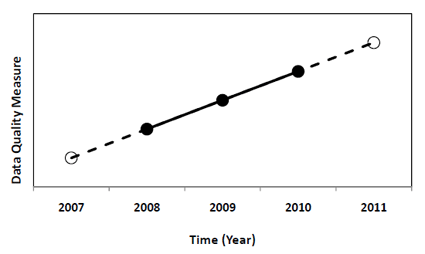 Figure 1. Schematic of Data Quality Extrapolation
Figure 1. Schematic of Data Quality Extrapolation
Generalized Validation Guidance
The validation team needs to identify the purpose and requirements of the validation and obtain an extensive knowledge of the (potential) users of such validation results. Involving all stake-holders in the decision process ensures the support for validation and acceptability of its results by all parties. Therefore, it is a good practice to keep a close contact between validation team, private sector data provider, and public sector users to address all the concerns and to incorporate all their constructive suggestions both in the planning process and throughout actual data collection and implementation phase. Since a validation effort at the national/regional scale will be highly visible, it is reasonable to expect that typical data providers require complete transparency of the validation process. Aside from gaining providers backing of the validation process and its results, transparent validation has the additional benefit of helping providers to spot shortcomings in their proprietary processes and work on fixing or improving them, the end result of which would be improved data quality for all users of that data. Developing a real-time data validation plan is comprised of taking the following steps:
- Technology selection
- Sample design
- Logistics planning and coordination
- Data quality measures
- Data handling, reduction, analysis and storage
In practice, several notable and tested technologies for accurate travel time data collection are available. These methods can be categorized into two umbrella groups, that are tracking and identification. Tracking methods obtain travel time of a single or a representative group of vehicles in traffic stream by tracking them over a stretch of the highway of interest, effectively building the vehicles trajectories. On the other hand, identification techniques follow the notion that once a characteristic signatures of vehicles passing at two different locations are identified a comparison between the pair of passage time stamps would produce the vehicle travel time between the two identification locations. The following is a list of different travel time data collection technologies that fall within these two broad categories and are widely used to establish "ground truth" in travel time validation efforts:
- Tracking methods:
- Floating vehicle
- Probe vehicles
- GPS receiver
- Cellular phone
- GPS on cellular phone
- Identification methods:
- Signature matching
- License plate
- Toll tag
- Magnetic
- Bluetooth
Both tracking and identification methods collect data that needs to be cleaned before use in travel time estimation. The effort needed to clean the collected data set varies greatly from method to method depending on the cleaning technology used and the operator's expertise level. Also, the degree to which the produced number of travel time observations can be a representative of the traffic stream is another factor that needs to be taken into consideration when deciding which method to use.
Table 4 summarizes the results of a recent survey on Bluetooth traffic monitoring system manufacturers in the US market conducted by the University of Maryland in January/February 2011. In this survey five companies were initially identified as producers of various types of Bluetooth sensors. Out of the five companies, four agreed to provide their system specs and pricing details for the purpose of this report. It is notable that for validation purposes and to maximize flexibility of the sensors, stand-alone direct current (DC) powered systems are preferable as it would be possible to deploy them practically at any location without worrying about the power supply. The DC powered units typically include a car-size battery that can be fully recharged in 48 hours and hold enough charge for up to 10 to 12 days of continuous data collection. In authors opinion even though real-time data processing is potentially capable of realizing on-going monitoring and data quality validation, in general, post processing the data is, more preferable option since in addition to being more economical, it allows for convenient incorporation of the lessons learned in the validation process as well as dissecting the collected data sets to any desirable level.
Table 4. Known Bluetooth Traffic Monitoring System Manufacturer Features in the US Market
| Company Name |
System Types Offered |
Processing |
Price
(US $) |
| Post Oak Traffic |
Permanent/Semi-permanent/Portable (suitcase type) - DC or alternating current (AC) powered |
Real-time / Post processing |
4,500/Bulk discount available |
| Traffic Cast |
- AC with cellular Communication
- AC with Ethernet Communications
- AC with Cellular and Ethernet Communications
- DC with cellular Communication
- DC with Ethernet Communications
- DC with Cellular and Ethernet Communications
|
Real-time / Post processing |
1,000 to 5,000 |
| Savari Networks |
AC/DC powered or power over Ethernet |
Real-time |
4,900 |
| Traffax |
DC powered |
Post processing |
4,000 |
As noted in table 4, the unit price of each DC powered Bluetooth sensor with post-processing capability is in the $4,000-$5,000 range. In comparison, a leading license plate matching camera has a price tag of $16,000-$18,000.
After appropriate validation technology(ies) is(are) selected, the number of samples needed to draw meaningful conclusions about the accuracy of private sector provided travel time data need to be determined. This task should be accomplished with validation budget constraints and precision requirements in mind. Too many samples may translate into a costly validation, while too small a sample will not be able to provide enough precision. At any rate, the trade-off between sampling economics and sampling precision has to be taken into consideration at all times.
From a practical perspective, it is natural to assume that segments prone to more variations in travel time (both in terms of frequency and magnitude) are more desirable test segments than the ones with relatively stable travel times under extended periods of time. Similarly, time periods in which most fluctuations in travel time are expected to happen make for better sampling periods. In this respect, the challenge is to identify the optimal set of segments and time frames over which to perform data collection so that the maximum gain can be achieved from the validation effort.
Additionally, when considering travel time data from multiple sources, it may become necessary to take into consideration significant attributes of the data providers as well in designing a sampling strategy. Attributes such as technology(ies) used by the provider to generate and deliver travel time data, its market penetration, maturity, reputation and most recent data quality measures and whether they are improvements over older results or not can be helpful in putting together a viable and efficient sampling plan for validation.
Actual data collection requires detailed answers to specific questions such as where—with exact lat/long precision—and when (Tuesday morning at 8am as opposed to Monday evening at 7pm), data collection should start and/or end. Based on experience, engaging local authorities in the planning process for data collection early on has always proved to be an essential factor in the success of the validation effort. Local input and support of the validation effort makes the process more efficient and smooth.
Developing a plan to engage state and local authorities including relevant law enforcement agencies (as required) prior to any real-time or archival data collection for validation purposes is necessary. All relevant information should be prepared and presented to relevant local agencies at least one month before the planned start of data collection. Authorities should then be asked to comment on the plan and propose improvements and any changes they deem necessary based on their local knowledge of potential safety hazards to the general public and their personnel, local and seasonal congestion patterns, construction projects in the area, weather conditions, etc. Every effort should be made to incorporate these comments in the modified data collection plan. A few iterations may be necessary before the final data collection plan is accepted by all parties. The final plan should address the issue of validation logistics in detail. Questions such as how relevant data collection equipment should be transported and deployed in desired locations in a manner that ensures the safety of the personnel involved should be addressed.
Data quality has always been an important concern in any ITS application. In recent years, the issue of developing quality measures for different travel related data has been of special interest because of the emergence of private companies which provide traffic information to the public agencies. Two data quality measures that are widely used for travel time data validation purposes are "average absolute speed error" and "speed error bias." Here by speed we mean average travel speed. Typically, data quality requirements should be in effect whenever the traffic volume is higher than a certain level on the segment of interest. These measures should be calculated and verified separately in different speed ranges. A typical speed partitioning system for freeways is: below 30 miles per hour (mph); 30 mph to 45 mph; 45 mph to 60 mph; and greater than 60 mph. It is important to note that the validation speed or the "ground truth" speed is considered as the basis for speed range definitions.
It is expected that large scale validation efforts will result in massive amounts of data that is to be collected and processed. For this reason the validation team should plan for data warehousing and determining the necessary information technology platform and software that is needed for validation.
It is a common practice for private sector to report travel time data on TMC codes, which are supported by major map providers such as NAVTEQ and TeleAtlas. In the absence of any other standard, it is a good practice to collect validation data on TMC segments. The latest version of the TMC definitions must be incorporated into the data warehousing system. Additionally two or more TMC segments may be combined to form longer path segments for validation purposes. In such cases it is necessary to create a protocol for communicating the path information to all parties involved in the validation process.
If technologies such as Bluetooth are used for travel time sampling, major data processing effort for matching and filtering the raw records must be undertaken to prepare data for validation. In the case of I95 Corridor Coalition VPP, over 6 million travel time samples have been collected resulting from over 30 million raw Bluetooth detections. An appropriate database system is crucial for archiving, manipulating and preparing such data. If multiple technologies will be used for ground truth data collection, it is of particular importance to standardize the data coming from different sources before adding them to the data pool.
The recommended approach is a hybrid of all three approaches.
- Statistical process control analysis should be used on a nationwide basis to identify locations or time periods of suspect data.
- High-quality or trusted public sector traffic data should be identified and used on a selective basis to compare against private sector data. The locations or time periods with the most suspect data (as identified with the statistical process control) will be the highest priority for evaluation purposes.
- The quality of real-time data should be selectively evaluated by using portable, short-term field data collection (e.g., Bluetooth-based) at those locations with the most suspect data. Obviously, this approach should be used where there is no nearby trusted public sector data sources.
Another approach will become feasible as the Section 1201 travel time data accuracy specifications are implemented by state DOTs. Essentially, this approach relies on the state DOTs to assess and ensure that their real-time travel time data meets the accuracy requirements in Section 1201, thereby ensuring that the resulting historical averages will be at least that quality level, if not better.
July 2011
FHWA-HOP-11-029