Behavioral/Agent-Based Supply Chain Modeling Research Synthesis and GuideCHAPTER 4. AGENCY EXPERIENCES WITH BEHAVIORAL/AGENT-BASED SUPPLY CHAIN MODELSThis chapter details the comprehensive review of the state-of-the-practice models. The models reviewed are summarized along 12 dimensions related to methodology and data. The information in this chapter is based on the information collected and reviewed from the public agencies identified in Chapter 1. Models are presented in order of development date, from earliest to most recent. CHICAGO METROPOLITAN AGENCY FOR PLANNINGMethodologyThe Chicago Metropolitan Agency for Planning (CMAP)1 has been incrementally building a regional freight model since 2010. CMAP first developed the firm synthesis, supplier selection, and mode choice elements of its freight modeling system (Cambridge Systematics, 2011). CMAP then added supply chain and logistics elements and truck-touring models (RSG, University of Illinois at Chicago and John Bowman, 2012). Finally, CMAP (RSG, 2017) developed an extension to the mesoscale model, a modeling tool for forecasting future freight flows under different sets of investment, policy, and macroeconomic scenarios. The mesoscale model extension can help analyze industries and answer questions regarding how such industries might affect the freight-dependent business community. Supply Chain Modeling NeedsCMAP developed a freight forecasting model for policy and planning sensitivity analysis to systematically vary forecasts to reflect potential changes in macroeconomic conditions (e.g., foreign trade levels, price of crude oil); large-scale infrastructure changes (e.g., port expansions, new intermodal terminals); technological shifts in logistics and supply chain practices (e.g., near-sourcing, outsourcing, productivity enhancements); and other assumptions and scenario inputs related to the economic competitiveness of the Chicago region and its infrastructure investments. CMAP also intends to use their freight forecasting model to evaluate performance of local freight facilities (e.g., transfer terminals, roads, rail, water, and air cargo infrastructure). The Chicago region's long-range comprehensive plan calls for the development of robust modeling tools to address the local and regional effects of freight transportation-based changes in the economy and freight delivery systems. CMAP desires an analysis tool that explains the economic choices made for goods movement across multiple modes and commodities, and that provides a picture of the region's role in the national freight economy. Once the updated model (currently under development) is ready to use, initial efforts will focus on providing an understanding of how freight currently moves throughout the region. As a start, CMAP freight planning staff may be interested in evaluating the regional impacts of freight policies such as overnight delivery ordinances or the expansion of logistics terminals within the region. Model Structure, Component Interactions, and SegmentationThe national-scale portion of the CMAP freight model addresses how establishments that buy goods select suppliers and how suppliers ship goods to their buyers. Figure 12 presents the CMAP national-scale model structure process. 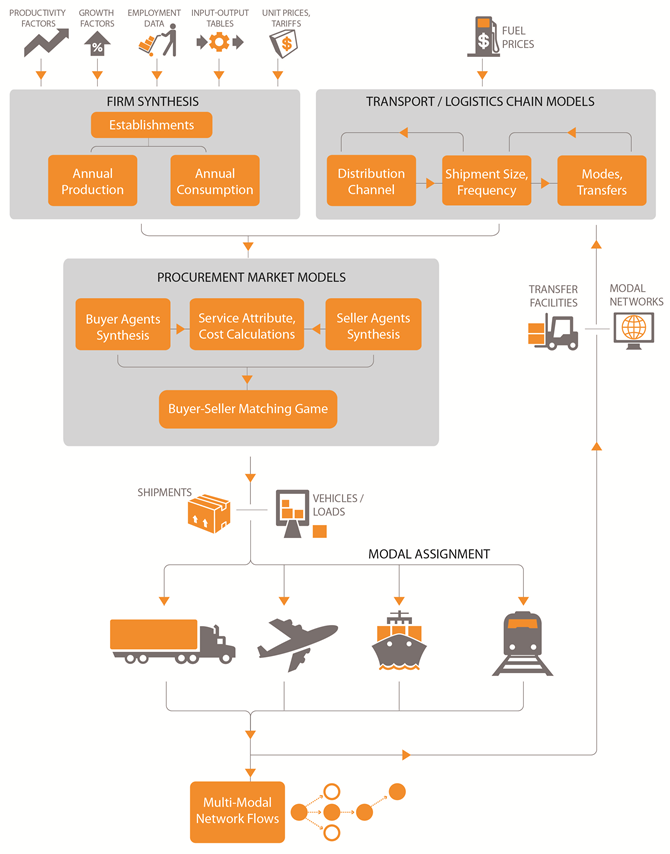
Figure 12. CMAP National-Scale Supply Chain Model Process.
Initially, the model synthesizes establishments across the United States by industry and size category. The model then determines the complexity of the distribution channel used in the supply chain. Multinomial logit choice models determine the supply chain type based on buyer-supplier pair characteristics and industry characteristics. The four chosen distribution channels represent complex supply chains rather than a single supply chain. The national-scale models identify the shipment size, frequency, and mode of shipments based on travel time and cost and the characteristics of the shipments and distribution channels. CMAP uses a flexible agent-based computational economics approach for modeling the evolution of regional supply chains, as influenced by key economic drivers. The model starts by synthesizing U.S. establishments by industry classification and size, locating them spatially, and deriving annual production and consumption requirements from existing commodity flow relationships between producing and consuming sectors of the national economy, as represented in U.S. Bureau of Economic Analysis benchmark IO accounts data. The model system also synthesizes agents representing establishments in countries and industries that currently trade with the United States. For each commodity market, an iterative procurement market game (PMG) is played. The PMG involves a pool of buyers who attempt to procure inputs from a pool of sellers in the market. As an input to the PMG, the transport-logistics chain models simulate the choice of distribution channels, shipment sizes, and modes for each prospective buyer-supplier pair, thereby enabling the calculation of logistics costs and shipping times. Buyers consider shipping times, unit costs (transport and nontransport), and risk minimization (e.g., supply chain disruption). Sellers, who are capacity constrained, evaluate whether to trade with a buyer in the face of other, potentially more lucrative offers. Through repeated bilateral games, agents form preferences for specific trading partners based on past interactions and may adjust their tolerances for risk based on market constraints. The final round of the game (after a user-specified number of iterations) indicates which agents established trading relationships and the quantities of commodities bought and sold, producing a set of spatially distributed freight flows between establishments located in freight analysis zones. In most markets, buyers will far outnumber sellers; however, buyers will likely purchase commodities from multiple sellers, either for risk-minimization reasons or limited individual seller capacity. Because foreign buyers and sellers are included in the procurement market, the model also predicts import and export flows. The regional-scale truck-touring models were developed as integrated elements of the freight modeling system, with direct inputs from the national-scale supply chain models. The model produces trip lists for all the freight delivery trucks in the region that can then be assigned to a transportation network. The truck-touring model components predict the elements of the pick-up and delivery system within the Chicago region through several modeling components, as shown in Figure 13:
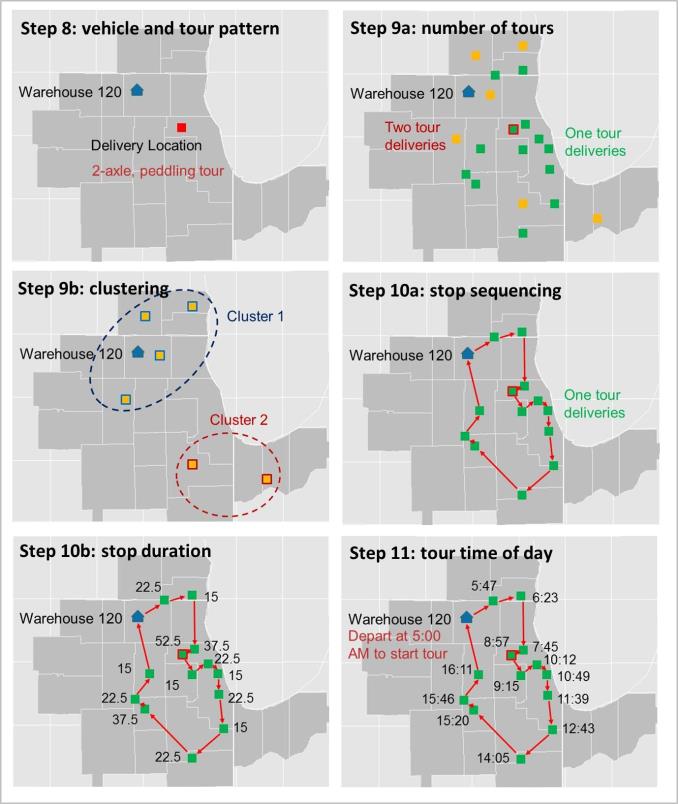
Figure 13. CMAP Regional-Scale Truck-Touring Model Process.
The model simulates the evolution of globally connected supply chain relationships in the Chicago region and how these trading relationships translate to regional freight flows defined by industry, commodity, size, and mode. The buyer-supplier matching component operates as a processing kernel within the larger mesoscale freight model to simulate the evolution of supply chain relationships, rather than allocating a fixed freight demand. The regional tour-based truck model component evaluates the performance of existing and future regional freight facilities. Market Segmentation (Industry, Commodity, Mode, Vehicle Type, Temporal, Activity Type)The CMAP freight model employs several types of market segmentation depending on the unit of analysis of each model component:
Assumptions Made Regarding Agent/Behavioral RelationshipsThe model makes various assumptions regarding inputs to the model and relationships between buyer and seller agents. For example, in the PMG kernel, some input parameters reflect different assumptions regarding buyer tradeoffs between supplier cost and responsiveness and risk hedging. In addition, different sets of parameters and payoff weights are specified in the model to reflect assumed information available to agents and whether market prices are static or adjusted throughout game play. In general, PMG behavioral parameters reflect assumptions about the possible mindsets of buying and selling agents as they seek out and try to secure favorable procurement contracts for their establishments. The CMAP model recommends a baseline set of PMG parameters, motivated by the aspiration to represent plausible agent behavior under the following assumptions:
Also, for import/exports of commodities, it is assumed that the amount produced by each country for a commodity represents a fixed production capacity (supply), and ignores the demand-supply impacts of sales to non-U.S. countries. Similarly, the model assumes that the amount that the United States exports to each country represents a fixed demand for U.S. goods and ignores the demand-supply effects of purchases from non-U.S. countries. Modeled Performance Measures
Approach to ForecastingThe CMAP freight model is run as a standalone scenario (currently only a base year exists) through RStudio software. The truck-touring component of the freight model outputs a set of time-of-day truck trips in CMAP's modeling zone system that can serve as inputs to the regional trip-based model in place of the current truck demand used within the model. CMAP has verified that this functionality works but has not yet used freight model truck trip tables for any planning analysis. CMAP has not developed any actual scenarios for the PMG version of the freight model. A consultant contract is underway that will develop and test at least one alternative scenario for sensitivity testing purposes. This work will include the development of methods and procedures to modify input data as appropriate. Types of Applications and ProceduresThe current freight model is still in the development phase and has not been used for any planning analysis. The current consultant contract will calibrate the mode choice component of the freight model and will validate the model's output commodity flows. CMAP staff will begin to use the model for planning analyses after this work is completed (anticipated by the end of 2017). To date, CMAP has applied this system to a limited set of sensitivity tests (constrained to varying the PMG input parameters for a set of selected commodity markets). DataGeographic ScopeThe CMAP freight model has multiple levels of resolution and can forecast freight flows between Chicago and the rest of the world (mesoscale). It also includes an intraregional truck-touring model (microscale). The different systems (meso and micro) are used for apportioning high-level commodity flows to individual shipper-receiver pairs and identifying the set of feasible transport paths for each shipper-receiver pair:
Figure 14. CMAP Statewide TAZs.
Figure 15. CMAP Regional TAZs.
Data InputsThe CMAP freight model uses the following data sources as data inputs:
Data Used for Estimating Model ParametersThe CMAP freight model uses the following main data sources for estimating model parameters:
Data Used for Model CalibrationUnder the new model update contract, CMAP expects to calibrate the mode choice model used to estimate shippers' choices. This is anticipated to be accomplished by comparing the freight model-derived modal shares used to transport significant commodities or commodity groups within the national economy to modal shares reported by other data sources. These data sources may include (but are not limited to) the FAF data, the Public Use Waybill Sample, Waterborne Commerce Statistics Center data, and the 2012 Commodity Flow Survey (CFS) Public Use Microdata (PUM) file. Data Used for Model ValidationCMAP plans to validate the PMG portion of the model against observed commodity flows (e.g., FAF data) as part of the new model update work. Two types of validation will involve comparisons with observed data where data are available, and in cases where data are not available, a process validation compares the outcomes of the model with anticipated outcomes based on the mathematical algorithm that the model is intended to simulate. The validation will examine several outputs from the firm synthesis and procurement market models that collectively lead to the shipment flow outputs produced by the model (e.g., location and magnitude of commodity production and consumption, spatial commodity flow patterns, and magnitude of commodity flows). The validation process design will depend on identifying what data are available to support validation. The geographic scale achievable using the FAF data is likely limited to FAF zone to FAF zone, which is essentially State or major metro area to State or major metro area. The validation task will likely rely on a similar set of datasets to those used to calibrate the mode choice model. Data Desired, but not FoundSome of the desired—but unobtainable—data for use in the model included the following:
Detailed information about the model and the freight datasets is not yet available online. FLORIDA STATEWIDEMethodologyThe Florida Department of Transportation's Freight Supply Chain Intermodal Model (FreightSIM) (RSG, 2015) is a travel demand model component integrated into the Florida Statewide Model (FLSWM). FreightSIM simulates the transport of freight between supplier and buyer businesses in the United States, focusing on Florida-specific movements. FreightSIM produces a list of commodity shipments by mode and converts those to daily truck trip tables that can be assigned to the national and statewide networks in the FLSWM along with trip tables from the passenger model. The approach used in the development of FreightSIM employs supply chain and economic methods to explicitly model aspects of freight decision-making behavior. The model is intended to provide decision-makers with better information to make decisions about transportation investments and policies. The supply chain methods at a national scale in this framework have been adapted to include additional level of detail (zone system) in Florida. Supply Chain Modeling NeedsProviding freight mobility in a cost-effective manner requires an understanding of supply chain and logistics behavior and an evaluation of investments in transportation infrastructure and services. It also requires anticipating the effects of any government and private sector decisions that affect the transportation system and its uses. The development of a multimodal supply chain shipment model was focused on addressing this overall objective. Trends affecting freight mobility in Florida over the next 50 years include an innovation economy with emerging mega-regions and industries such as aerospace, clean energy, life sciences and creative industries; shifting global markets and development patterns; new communication technologies and environmental stewardship challenges; and the changing role of the public and private sectors (Florida Department of Transportation, 2010). Challenges for the transportation system arising from these trends include: efficient and reliable connectivity as a global hub, congestion on intercity corridors, new logistics practices, sustainable environmental practices, and available funding. A multimodal supply chain shipment model of goods movement for Florida was developed to assist with the following:
The goal for FreightSIM is to account for changes to freight mobility based on these types of policies. Model Structure, Component Interactions, and SegmentationFreightSIM simulates the transport of freight between each supplier and buyer business in the United States. Figure 16 illustrates these processes and identifies major input and output data. This modeling system includes the selection of business locations and trading relationships between businesses; it also includes the resulting commodity flows, distribution channel, shipment size, and mode and path choices for each shipment made annually:
The model incorporates a multimodal transportation network that provides supply side information to the model, including costs for different paths by different modes (or combinations of modes). The model encompasses all of Florida and freight flows between Florida and the rest of the world. Truck flows are assigned with passenger trip tables to highway networks to produce auto and truck volumes across the United States. The validation data are for rail, air, and waterway flows and these data are retained as trip tables instead of being assigned. 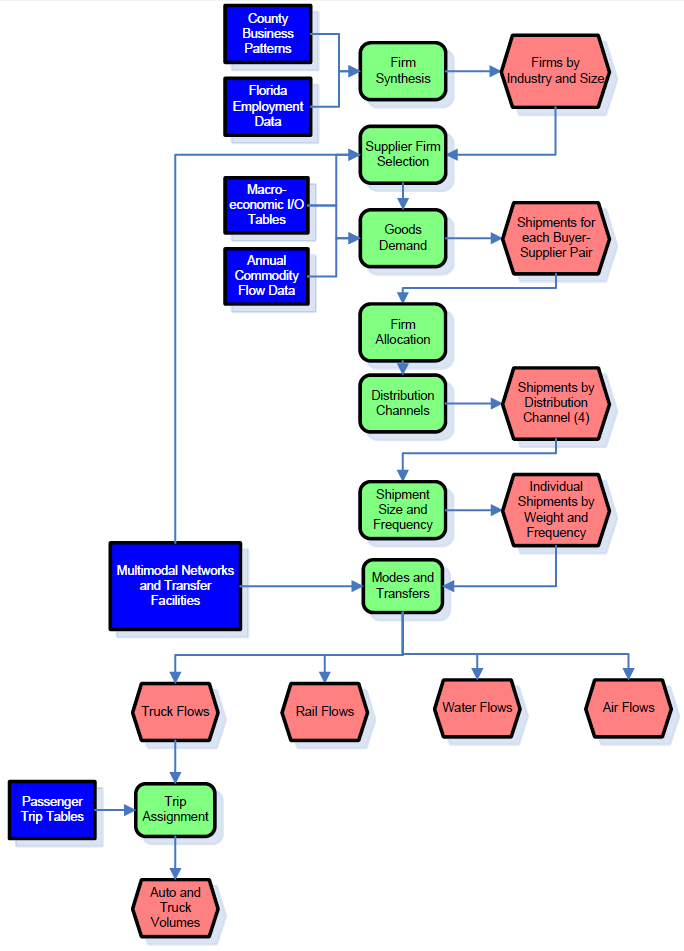
Figure 16. CMAP Regional-Scale Truck-Touring Model Process.
Market Segmentation (Industry, Commodity, Mode, Vehicle Type, Temporal, Activity Type)FreightSIM employs several different types of market segmentation depending on the unit of analysis of each model component. The firm synthesis model characterizes business establishments by location (TAZ), establishment size (eight employment categories ranging from 1–19 employees to over 5,000 employees), and industry (six-digit Census Bureau NAICS categories). The firm synthesis model is controlled at the TAZ level within Florida using the statewide employment forecast data. The employment forecasts are grouped into three employment categories that are aggregations of NAICS categories. The commodity production and consumption by business establishment uses the BEA's six-digit NAICS categories, which is slightly aggregated in comparison to the U.S. Census Bureau's NAICS categories used for the industrial classification of the business establishments. The supply chain model works with FAF commodity flow data and uses the 43 SCTG categories for segmentation of shipment commodity. The distribution channel of the shipment flow through the supply chain is segmented into direct shipments using one, two, or three transfers at distribution centers or intermodal transshipment locations. The supply chain model allocates shipments into size categories using a two-stage process, ultimately calibrating the distribution to the nine shipment-size categories, ranging from less than 50 pounds to more the 100,000 pounds used by the CFS. The shipments are allocated to one of four main modes (i.e., truck, rail, water, or air), with the intermodal paths being some combination of those modes (e.g., truck-rail-truck). The conversion to trip tables of the outputs from the supply chain model uses truck percentages for light, medium, and heavy trucks (FHWA classes 2–3, 4–7, and 8–13, respectively). The trip tables are divided into four time-specific trip tables (AM peak, midday off-peak, PM peak, and nighttime off-peak) using fixed factors. Modeled Performance MeasuresFreightSIM includes the following performance measures:
Approach to ForecastingThe freight demand, supply chain, and mode and transfer components of FreightSIM are run for each forecast year using the R open-source statistical programming platform and are integrated with the FLSWM that is implemented in the Cube software. The statewide model includes the following primary groups or steps:
FreightSIM's trip table outputs are combined with those from the other components of the model—nonfreight trucks and passenger trips—and assigned to the highway network in the final model step. FreightSIM requires travel time and costs from future-year highway networks and nonhighway freight networks, future-year commodity flow forecasts (e.g., FAF data forecasts or alternative commodity flow forecasts developed by the model user), future-year employment controls at the TAZ level, and future-year distribution center locations to create a future scenario. Any additional future-year inputs required to develop future-year passenger vehicle forecasts are also required to run a full statewide model scenario for all travel, such as household and population forecasts. Types of Applications and ProceduresThe FreightSIM multimodal statewide supply chain shipment model could support multiple types of policy analyses:
FreightSIM is designed to be a policy sensitive freight model with the following applications:
DataGeographic ScopeFreightSIM uses three levels of spatial resolution:
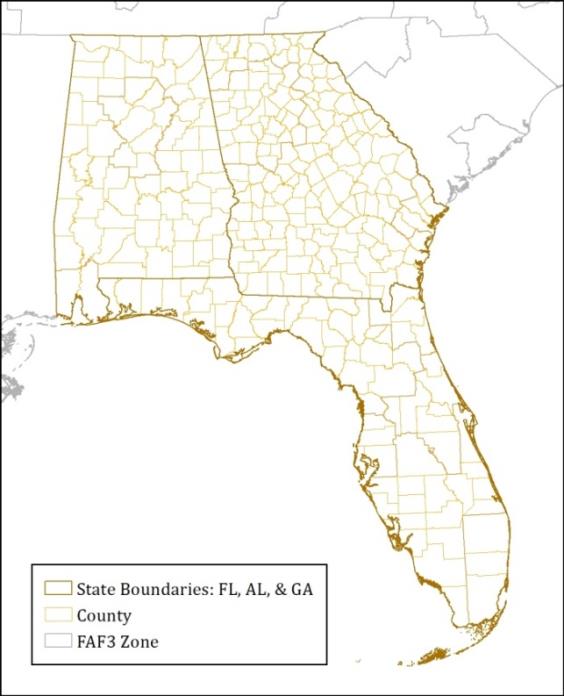
Figure 17. FAF Zones and Counties In Florida, Georgia, and Alabama.
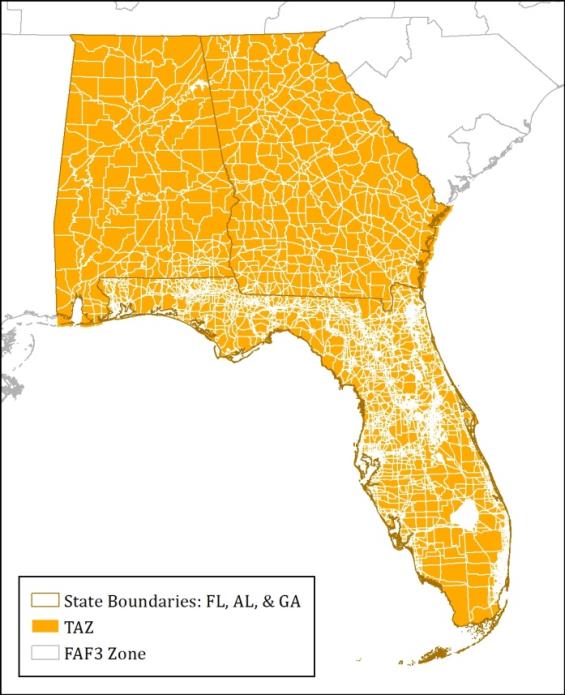
Figure 18. Statewide Traffic Zone System (Florida, Georgia, and Alabama).
Data InputsSeveral data inputs were used for FreightSIM's development, both as main inputs or as additional, miscellaneous datasets. Table 4 lists a summary of the main inputs that are required for the model. This table lists each input and describes its source, the module(s) where it is applied, and an overview of the data.
Source: (RSG, 2015)
Data Used for Estimating Model ParametersFreightSIM uses the following main data sources for estimating model parameters:
Data Used for Model CalibrationFreightSIM uses the following main data sources for model calibration:
Data Used for Model ValidationFreightSIM uses the following main data sources for model validation:
Table 5 shows the details of validation tests.
Data Desired, but not FoundSome of the desired—but unobtainable—data for use in the model included the following:
Detailed information about the model and the freight datasets is available online at:
WISCONSINMethodologySupply Chain Modeling NeedsThe Wisconsin Department of Transportation's (WisDOT's) main needs from its freight model are forecasts of truck volume on the roadways. WisDOT maintains data on the commodities being moved, and the origins and destinations of freight moving to, from, and through Wisconsin. WisDOT uses its freight model to answer the following questions:
WisDOT requires forecasts of trips by all modes that carry freight—not just trucks—to prepare these truck forecasts, evaluate changes in modal share, and provide forecasts of freight travel by other modes. Further, Wisconsin needs accurate tools and data for evaluating freight corridors entering Wisconsin, and for freight facilities in counties/metropolitan areas adjacent to Wisconsin. WisDOT currently operates a vehicle trip-based model (where trips by different modes are not linked into supply chains). WisDOT has tested a supply chain model where the cargo carried by those trips are linked. According to WisDOT, the supply chain model as it was currently formulated, did not do a good job of evaluating changes in truck volume given changes in the socioeconomic characteristics of a given area, which was related to limitations inherent in the input data available. The inherent limitations of the input data are primarily related to the coarse granularity of the O-D freight flow data available to WisDOT (the FAF data). In one analysis scenario conducted as part of the model development, the model predicted fewer trucks going to and from Kenosha County—with the presence of a newly constructed Amazon fulfillment center there—than without it. As tested by WisDOT, the supply chain model accurately predicts changes in mode shift due to changes in the use of supply chains or system inter-modality. In a different analysis scenario conducted as part of model development, the model showed that given the presence of an intermodal rail terminal in Milwaukee County, there would be an increase in mode share by rail containers in Wisconsin and nearby Minneapolis, Minnesota, and Rochelle and Chicago, Illinois. However, only a small portion of this freight tonnage was taken away from trucks, which are by far the dominant mode of freight transport in Wisconsin. (The supply chain model showed more rail tonnage taken away from the Minneapolis-area intermodal terminals than from the closer and more active Chicago terminals—this is counterintuitive to the expectations from adding a Milwaukee intermodal terminal.) According to the agency, the short- and long-term applications of the WisDOT supply chain freight model are unclear at the time of writing this synthesis. The primary need of WisDOT from its freight model is to conduct evaluations like what was described in preceding paragraphs; WisDOT thinks that the supply chain model does not accurately evaluate truck volumes. There may be commodities or commodity groups where one model is preferable to another, particularly for mode allocation. For bulk commodities, the supply chain model seemed to slightly overestimate truck allocations, while also underestimating rail volumes. For finished goods, the supply chain model seemed to reverse this bias, with the rail mode seeing higher estimates than identified under the FAF. This appears to be a legacy of the origins of the modified Wisconsin supply chain model in the Chicago-area metropolitan planning organization's model; the presence of many intermodal facilities in the Chicago region allows greater opportunity for rail shipments of finished goods than in Wisconsin. Further, some freight movements are more conducive to a chain model, while others are better represented through O-D modeling. Examples of supply chain trips for Wisconsin's freight include the collection of milk by tanker trucks, the distribution of fuel oil or propane, and the wholesale or corporate distribution of consumer products at multiple retail locations. Meanwhile, the O-D model best captures the movement of wood to paper mills, sand, and other aggregate to processing facilities, and coal to utility plants. Should the FAF be refined down to smaller regions, then that data could be used to test and compare the supply chain model with Wisconsin's existing trip-based model. Such a test could apply each model to a selection of typical bulk, semi-finished, and finished goods, evaluating the accuracy of that model against specific freight categories or commodities. The refined data would also better identify corridors and modes used for cross-border and multistate freight movements. Model Structure, Component Interactions, and SegmentationThe Supply Chain Model includes the following component models:
Figure 19 shows the Wisconsin freight model structure. 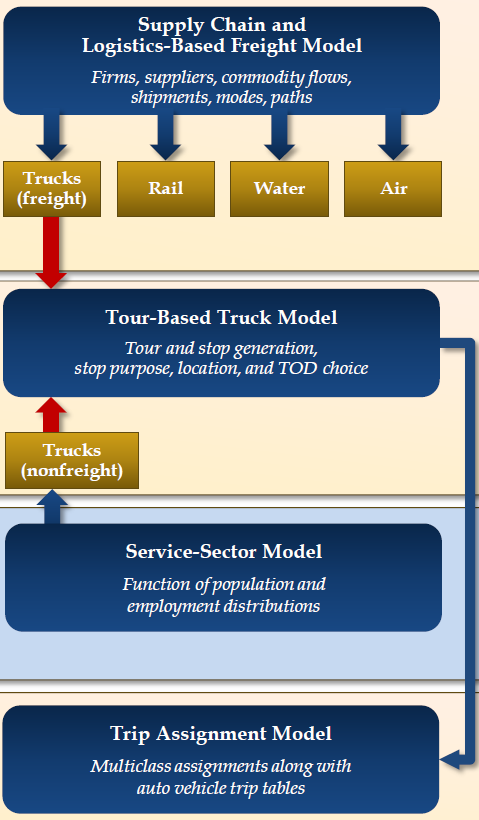
Figure 19. Wisconsin Freight Model Structure.
The service sector model is not part of the supply chain model developed for WisDOT and it is included here for illustrative purposes only. A supply chain tour-based truck model was developed for WisDOT, but it did not yield meaningful information regarding local truck tours due to the coarse granularity of the underlying FAF3 input data. The lack of meaningful information was also attributable to the forecast usage of truck tours exclusively within supply chains (only truck tours occurring as part of supply chains were tested). Market Segmentation (Industry, Commodity, Mode, Vehicle Type, Temporal, Activity Type)Table 6 shows commodities and respective industries in the model. The model includes five modes (See Table 7).
Source: (Cambridge Systematics, 2016)
Source: (Cambridge Systematics, 2016) The WisDOT's statewide supply chain freight model is an average daily model. Time-of-day assignment methods can be employed in tour-based truck models, but these were not employed in this test of the supply chain model for Wisconsin. The Wisconsin supply chain model forecasts multimodal cargo transport. Modeled Performance MeasuresThe performance measures that are modeled in the WisDOT's statewide supply chain freight model are mostly the traditional performance measures:
Approach to ForecastingThe WisDOT statewide supply chain freight model as tested, was controlled by the basic multimodal O-D patterns in the FAF data. The model did forecast changes in the allocations of those multimodal O-Ds among different supply chains, but it was unable to change the multimodal O-D table in response to changes to Wisconsin's economy. By contrast, WisDOT's trip-based statewide model does forecast the multimodal O-Ds of freight based on changes in Wisconsin's economy. Types of Applications and ProceduresWisDOT's statewide supply chain freight model was run on an R-Code platform and interface. It was not integrated with WisDOT's trip-based passenger model. Scenario creation typically involves making changes to network characteristics (like a proposed roadway capacity expansion or speed limit change) or socioeconomic characteristics (like proposed land development). All other model parameters are typically maintained between base and alternative scenarios. DataGeographic ScopeThe WisDOT's statewide supply chain freight model zone structure is national for the allocation among supply chains, with greater detail within and near Wisconsin. The model zone structure for supply chain freight zones are counties in Wisconsin and neighboring states, the remainder of FAF regions in neighboring states, and FAF zones in all other U.S. States. Data Inputs
Data Used for Estimating Model ParametersThe WisDOT model uses the following main data sources for estimating model parameters:
Data Used for Model Calibration/ValidationWisDOT performed a reasonableness check by aggregating the supply chain groups (e.g., direct truck, direct rail, air, water). Flows were also aggregated by commodity groups that were also used to renormalize the tonnages after the original allocation to supply chains. The results were then compared to the FAF modal and commodity group aggregations for calibration/validation. Since the allocation to supply chains were done to total tons over all modes, comparing with similar aggregations from FAF data means that the allocation worked correctly. The following main data sources were used for model calibration and validation:
Data Desired, but not FoundA county-level (or TAZ-level) multimodal freight cargo O-D table was the main data desired, but such an independent data source was not available for validation against the supply chain freight model's forecasts. Detailed information about the model and the freight datasets is not yet available online. PHOENIXMethodologyThe Maricopa Association of Governments (MAG), Arizona Department of Transportation (ADOT), and Pima Association of Governments (PAG) submitted a joint proposal to the SHRP2 C20 IAP to develop an operational megaregional multimodal agent-based behavioral freight model. The proposal was successful and in September of 2014 the work began. SHRP2 C20 IAP grant and additional support from the agencies provided necessary funding and in-kind contributions that allowed to successfully complete the project. The development took twenty-four months. As a result, a regional behavior-based freight transportation model was developed for the Arizona Sun Corridor megaregion for evaluating freight policy effects at the regional scale. Relevancy, importance, and timeliness of the model for the planning tasks was underlined by the fact that Arizona and the MAG region in particular rebounded from the recession. Arizona Sun Corridor megaregion, which includes MAG region, continues to be one of the fastest-growing megaregions in the country. Supply Chain Modeling NeedsMAG, ADOT and PAG staff identified a need for the future development of the regional freight forecasting models. Arizona's Sun Corridor megaregion covers portions of five counties that include the MAG and PAG regions and is home to 8 out of 10 Arizonans. The Sun Corridor is also a major gateway for fresh produce and manufactured goods from busy freight ports on the U.S.-Mexico border. Arizona's population growth rate is expected to be robust in the upcoming decades and be one of the highest in the country, driven largely by activity in the Sun Corridor. FAF shows high growth rates in goods movement in Arizona. Given the expected growth in freight and its importance to the regional economy, MAG improved its capabilities to analyze freight demand in continuation of its state-of-the-practice truck models and developed a behavior-based freight modeling. MAG took a lead on the project and sought a behavioral-based freight modeling solution to support its organizational goals. MAG's goals included development of the regional transportation plan, development of freight transportation plans, and fostering transportation-related regional economic development. Moreover, MAG's extensive experience in developing and applying regional truck models led to a realization of the importance of behavior-based facets of freight decision-making. ADOT, MAG, and PAG realized that the decisions of shippers and carriers significantly affect regional transportation forecasting. A truck tour-based model recently developed by MAG resulted in noticeable improvements in forecast validations. The MAG's freight modeling tool addresses the changing conditions in freight supply and demand in the MAG region. It also captures transportation decisions, such as mode choice and the use of logistical handling facilities (e.g., intermodal yards) for individual establishments and simulates individual vehicle movements, allowing MAG to analyze impacts of new infrastructure projects at a highly detailed level. Model Structure, Component Interactions, and SegmentationThe proposed modeling framework, that largely remained intact throughout the development, is shown in Figure 20. This figure provides information on the data inputs necessary to apply the individual modeling components in the new model system, data necessary to estimate various components of the supply chain and tour-based models, the supply chain models, key outputs that are produced from each modeling component, different geographic zones, and data that will be used to calibrate each component and validate the new model system. The flow chart detailing implementation of the supply chain, transport, mode, and path choice models is shown in Figure 21. 
Figure 20. Individual Components Of The Proposed Behavior-Based Freight Model.
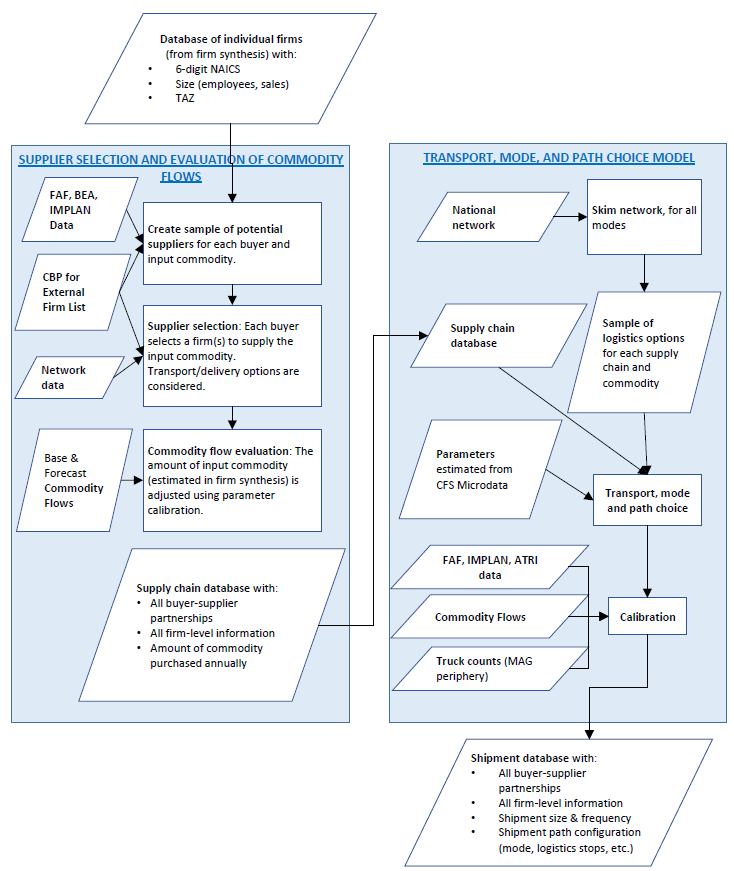
Figure 21. MAG Behavior-Based Supply Chain and Freight Transportation Framework.
Overall freight modeling framework included the following three major components:
Market Segmentation (Industry, Commodity, Mode, Vehicle Type, Temporal, Activity Type)Forty-two classes of commodities based on the SCTG were considered in this model (with the exception of SCTG 42 - Miscellaneous Transported Products). Each class of commodity is considered as an independent economic market for which supply chains were determined. MAG staff developed Standard Transportation Commodity Code to SCTG crosswalk for two-digit codes to use the TRANSEARCH data for comparing the supply chain model output (including mode choice model) which were developed using the FAF data. The NAICS system is used for determining the industry class in the firm synthesis and supply chain models. Trip assignment of the truck trips was completed using the multi-class assignment technique for five vehicle types:
Modeled Performance MeasuresThe performance measures that are modeled in the MAG freight model are mostly the traditional performance measures along with some indicators from the supply chain model:
Approach to ForecastingThe approach to forecasting and model development were based on a few main methodological principles:
Types of Applications and ProceduresMAG uses its regional truck model for air quality conformity analysis, analysis of O-D patterns, bottlenecks, and infrastructure and land-use scenarios. MAG uses its freight model for forecasting. The newly developed megaregional freight model is tailored for more advanced analysis of economic policies and economic scenarios, including scenarios developed for areas that are outside of MAG's region but that affect its regional economy and freight flows. MAG planners (particularly the freight planning group) require freight model outputs. These outputs are also required by the MAG air quality division, MAG member agencies, and MAG member agency consultants. MAG also has commodity flow data—including TRANSEARCH data—at the TAZ level. MAG has used these data for future-year commodity flow forecasts, validation and calibration of freight models. DataGeographic ScopeThe MAG freight model simulates freight shipments to, from, and within the Arizona Sun Corridor megaregion, which covers the Phoenix and Tucson Metropolitan areas in Maricopa, Pima, and Pinal counties. This region is home to more than 80% of the State's residents. Figure 22 shows the extent of the Sun Corridor megaregion. 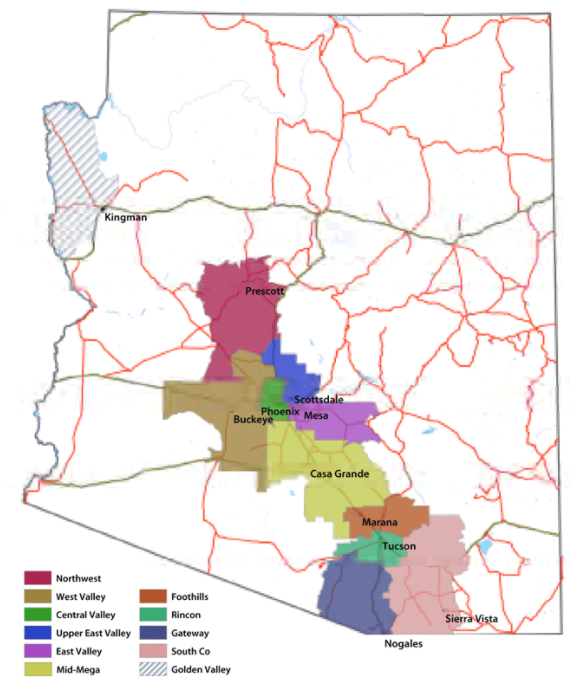
Figure 22. Sun Corridor Megaregion.
The model focuses on regional commodity flows to/from/within MAG/PAG region. However, a variable zone system was used for the framework, which comprises finer zones in the Sun Corridor for more detailed analysis and larger zones for the external areas to Sun Corridor. The zone system includes TAZs in the MAG/PAG region, counties in the rest of Arizona, and FAF zones for the rest of the country. Figure 23 shows the zone system used in this model. 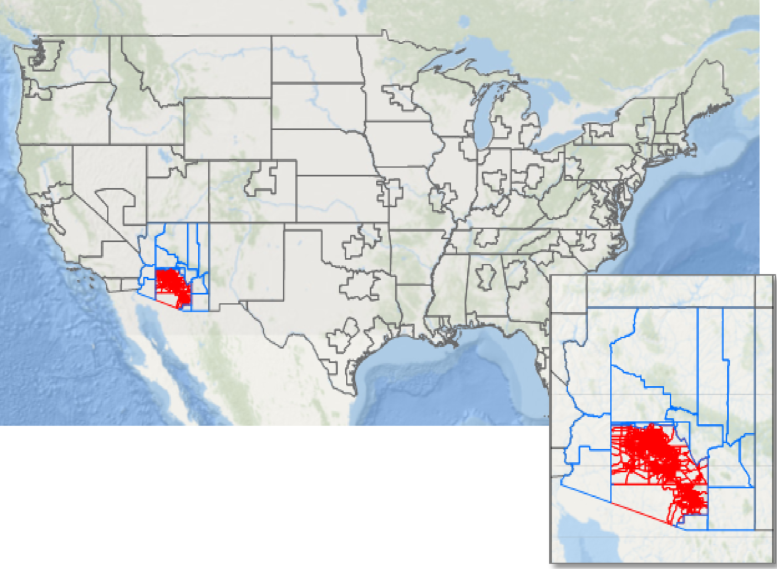
Figure 23. MAG Freight Model Zone System.
Data InputsFirm Synthesis model utilized the following main datasets:
The Supplier Selection Model used the following main datasets:
The transport, mode, and path choice models were developed using the following main data sources:
The tour-based truck model development process used the following main data sources:
Vehicle choice truck model development process used the following main data sources:
The process of developing independent networks for all main transportation modes that operate in Arizona used the following data sources:
Data Used for Estimating Model ParametersMAG utilized NETS data from 1991 to 2011 for estimating establishment birth rates by industry type. CFS, Public Use Microdata (PUM) was used to estimate parameters in the transport, mode, and path choice model. ATRI and Streetlight data was used for estimating truck tour models. The unit value of commodities was asserted from FAF data. The supplier evaluation criteria were drawn from FAF (cost), synthesized firms (quality, reliability), network skims (delivery), and the GIS shapefile of zone system (distance). The transportation costs used in path choice model development were asserted from various sources like USDOT's Research and Innovative Technology Administration, among others. Data Used for Model CalibrationThe calibration of the model included calibration of the supplier-selection model and calibration of the mode choice model. FAF4.1 data was the main data source for calibration of both models. FAF4.1 commodity flow patterns to, from, and within MAG/PAG region were used for calibration of the supplier-selection model and the modal split in the FAF4.1 data was used for calibration of the mode choice model. The regional TRANSEARCH data sample was also considered and analyzed for the model calibration. However, it was not selected for the final calibration due to several inconsistencies that were found between TRANSEARCH and FAF data. Data Used for Model ValidationThe portion of NETS data that is left out of estimation is used to validate the model. This smaller set comprised 20% of the establishments that were randomly selected to avoid introducing bias into either set. Also, MAG desired a sufficient and comprehensive supplier-selection information (an establishment survey can gather that data) but it was not available. The survey questions should be focused on gathering information on the supplier-selection process, such as the scoring process by establishments of different sizes and industries. InfoGroup data and the Maricopa County Employer Database were also utilized in validating the output from Firm Synthesis model. The assignment validation is done at two levels of geography. Screenlines analysis includes some of the major freeways that pass through the region and carry a large volume of trucks in the region. Data Desired, but not FoundData on the intermediate logistics nodes (e.g., consolidation centers, distribution centers) was desired but not available. The shipping chain choice could not be determined for truck shipments without these data. Instead, truck volumes were validated against observed count data. Lack of behavioral data on carriers, shippers, buyers, and suppliers effected the choice of the model methodologies. Detailed information about the model and the freight datasets is available online at the following websites:
OREGON STATEWIDEMethodologyOregon's economy is growing faster than the national rate. Despite this growth, the Oregon Department of Transportation (ODOT) has only modestly increased the capacity of their State's highway system to meet growing demand over the last 20 years. Traffic congestion is rising quickly, affecting passenger travel and freight movement alike. Reliability is also declining while transportation infrastructure is aging, and revenue streams are shrinking. Oregon is an export-dependent State, relying heavily on the transportation system to get goods to market via highway, rail, water, and air. When transportation costs rise, Oregon's jobs and products are affected. Questions related to the trade-off associated with investing and disinvesting in the Oregon transportation system have been explored using the Oregon Statewide Integrated Model (SWIM). SWIM is one of the several tools and methods used to answer these questions. SWIM can also be used to estimate commodity flows, which is valuable to decision-makers and important to understanding regional economies and how they rely on the transportation system. ODOT has recently completed the development of the latest version of SWIM (version 2.5). Previous versions of the model (SWIM 1.0 and SWIM 2.0) are now retired and not being used by ODOT. Supply Chain Modeling NeedsODOT developed SWIM to evaluate the impact of actions related to transportation at the statewide level. Representing the fundamental economic forces influencing transportation and land-use activity was paramount in the model design. The supply chain modeling simulated how commodities are moved as freight by different modes of transport, such as marine, rail, and truck for a typical weekday. For trucks, shipments are simulated to appropriately transport daily commodity shipments modeled by the business activity allocation module of SWIM. ODOT has used this tool to evaluate the impacts of weight restricting bridges, recovering from a major earthquake, planning to meet the future demands on the system while facing aging infrastructure, and shrinking funding streams. SWIM has also been used to evaluate the uncertainty associated with economic growth and external shocks, such as rising fuel costs. ODOT uses its integrated land-use transport economic model to answer the following policy, investment, and project assessments related questions:
Model Structure, Component Interactions, and SegmentationSWIM is an integrated economic land-use transport model covering the entire State of Oregon. SWIM system represents the behavior of the economy, land-use, and transport system in the State of Oregon and the interactions between them. The system is composed of a set of interconnected components that simulate different aspects of the full system. The structure of the overall model is shown in Figure 24. The following components are related to freight and commercial vehicle movements:
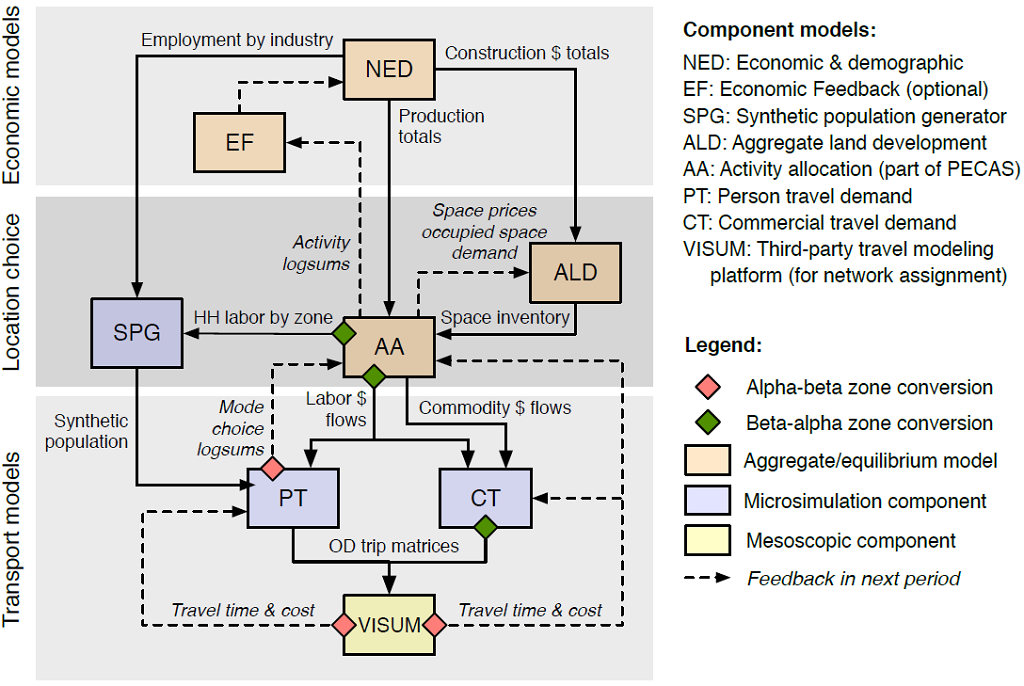
Figure 24. SWIM Overall Model Structure.
The model steps through time in one-year intervals, typically to a 20-year forecast horizon. The CT module is a hybrid framework that includes both aggregate and microsimulated data and models. The CT module includes several important dynamics unique to commercial vehicle travel:
Market Segmentation (Industry, Commodity, Mode, Vehicle Type, Temporal, Activity Type)The commodities produced and consumed in the model, including model area imports and exports, are tracked in the AA and CT components, including 39 types of goods based on the SCTG categories. Some commodity groups are combined to eliminate small commodity flows and simplify the model. The various modes and vehicles used in the model to transport goods flows are shown in Table 8. Non-truck freight modes are not assigned to the network.
Source: (WSP, ECONorthwest, HBA Specto and RSG, 2017) The industries defined in the NED and AA modules were built from data classified using different systems. IMPLAN data industries and NAICS code industries are used in these modules. Employment is forecast by IMPLAN sector (440 sectors) using a crosswalk and consistent with the official State economic forecast. Modeled Performance MeasuresODOT does not use SWIM to generate performance measures, but metrics are developed to meet needs of specific analysis projects from SWIM. The metrics that are modeled and reported in SWIM and are used as part of the measures to analyze policy questions depends on the reliability of the input data that is accessible for each analysis project and on the purpose of the application. Some of the metrics that SWIM produces include:
Approach to ForecastingThe SWIM system runs on a dedicated multiprocessor personal computer. The modeling system is run using a Python script, which is called using a DOS command window to automatically set up the required directory structure. The script calls each component module, and runs the model through time. Each run of the model has its own base scenario directory structure that is a complete reference scenario run and stores full model outputs. The model steps through time in one-year intervals, typically to a 20-year forecast horizon. The NED model provides the starting point with the economic forecast information built from external data and forecasts from the State revenue forecast. The NED module provides model-wide production activity levels, employment, imports, and exports based upon the long-range forecasts consistent with the Department of Administrative Services' Oregon Economic & Revenue Forecast and the associated baseline macroeconomic forecast from IHS Markit. NED provides the starting point for the population synthesizer, AA module, land-use model, and PT and CT model to simulate people and business activity. The CT module represents the flow of goods within the SWIM modeled area. It is designed to work closely with the AA module and complement the PT module. The current version of CT is written in the R statistical language, which is widely used at ODOT. Many of the models in the CT module are implemented as parallel processes using the doParallel package in R. The CT module reads the outputs produced by other modules and its own configuration and parameter files. Its output is a list of discrete truck trips and aggregate flows by commodity and mode. The CT program runs in 10–20 minutes, depending upon the number of cores and processor speeds. Types of Applications and ProceduresSWIM has often been used to evaluate the economic effects of different investment scenarios. Modeling work completed to date includes evaluating the effects of weight-restricting bridges on heavy trucks, recovering from a major seismic event, impacts of higher vehicle operating costs and evaluating future investment options as infrastructure ages, construction costs rise, and funding streams shrink. DataGeographic ScopeSWIM operates at two geographic levels within the modeled area, which is shown in Figure 25. Both geographic levels encompass 36 counties within Oregon and 39 counties in adjacent states. The latter is commonly referred to as the model's halo area. The halo encompasses a roughly 50-mile buffer around Oregon comprising 39 counties in Washington, Idaho, Nevada, and California. A system of 2,950 alpha zones (light and dark lines in Figure 25) is the most disaggregate zone system. These include 12 external stations, shown in Figure 25. These external stations serve as gateways to the six world markets used to represent the world beyond the halo. The six world markets link to the model transport network at the 12 external stations. 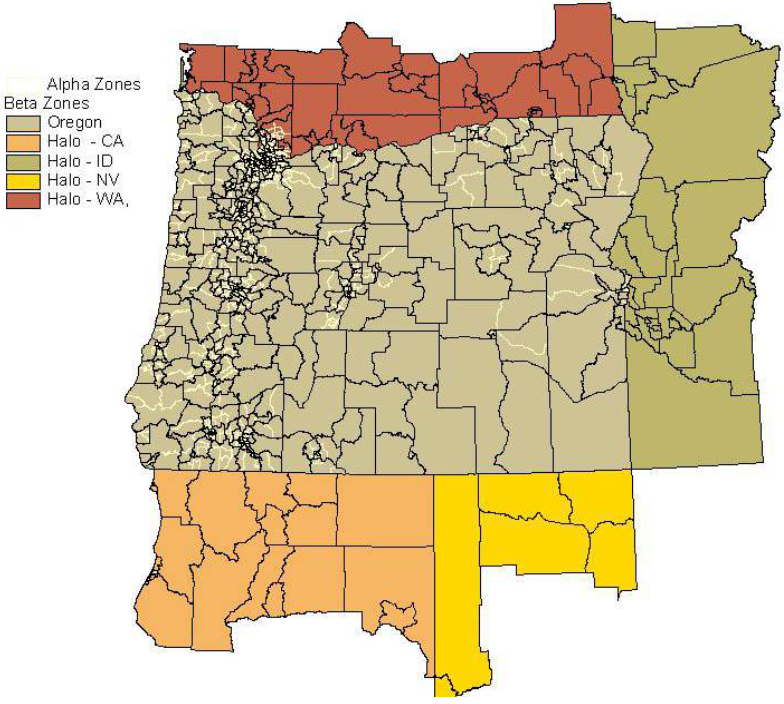
Figure 25. SWIM modeled area zone system.
SWIM represents the world outside of Oregon by FAF regions, which are aggregations of counties within the United States and countries or world regions outside of it. Within Oregon, the CT module operates at the alpha zone level. Because only Oregon and the halo are represented in the SWIM network, the interstate flows generated by CT module are routed through the external gateways. Data InputsODOT acquired and utilized the following datasets to develop the statewide supply chain freight model:
The current version of CT relies heavily upon the FAF to depict long-distance freight flows. Data Used for Estimating Model ParametersSWIM used the following main data sources for estimating model parameters:
Data Used for Model Calibration/ValidationSWIM used the following main data sources for model calibration/validation:
Data Desired, but not FoundTruck commodity flows by highway were the main data desired, but these data were unavailable. Detailed information about the model and the freight datasets is available online at the following website:
MARYLAND STATEWIDE/BALTIMORE REGIONMethodologyThe Maryland State Highway Administration (SHA) and Baltimore Metropolitan Council (BMC) model is a two-agency freight model developed as part of the Freight and Commercial Vehicle Model Development project. The model work was completed in part with funding provided to SHA and BMC by FHWA under a SHRP2 C20 Implementation Assistance Program grant. The SHA/BMC model comprises two major components that function at different geographical scales. The larger, national-scale model that is designed for integration with the Maryland Statewide Model (MSTM) maintained by SHA is a supply chain model that simulates the transport of freight between supplier and buyer businesses in the United States, focusing on movements that include Maryland. As with the FreightSIM model of Florida on which it is based, the supply chain model produces a list of commodity shipments sorted by mode and converts those to daily truck trip tables that can be assigned to the national and statewide networks in MSTM along with trip tables from the passenger model component of MSTM. The second major component of the SHA/BMC freight model is a truck-touring model of the Baltimore modeling region, a 10-county area of Maryland. This regional portion of the model is a truck-touring model that simulates both freight trucks (using the supply chain model's shipment list as a demand input) and nonfreight commercial vehicles (using demand generated independently of the supply chain model). Supply Chain Modeling NeedsSHA and BMC's application for the SHRP2 C20 grant outlined the planning needs that the SHA/BMC model is intended to support and was used to inform the development of the supply chain model. The agencies sought to develop modeling tools that provided some understanding of the connections between the region's economy, the resulting demand for freight movement, and the performance of the transportation systems. Three objectives informed the design of the model and supply chain modeling concepts:
The SHA/BMC model's design is a joint supply chain and truck-touring model where freight flows to and from the region influence vehicle movements at the local level to provide the desired modeling connections. For example, changes over time in the freight flows to and from a region influence the demand for long-distance truck travel and influence the need for additional local truck movements to facilitate local deliveries and pick-ups of shipments. The SHA/BMC model's geographical extent was designed to capture the full influence of the supply chains of shipments to and from the region. This model represents business establishments across the country and global suppliers and buyers who produce imports and consume exports. The model structure supports scenario testing to understand the effects of changes in the economy over time, including different patterns of long-haul domestic flows and imports and exports as domestic and international trading partners change. Model Structure, Component Interactions, and SegmentationThe SHA/BMC model includes a national supply chain model (NSCM) and an urban truck-touring model, including the freight truck-touring model (FTTM) for freight and the commercial vehicle touring model (CVTM) for non-freight-carrying trucks. Figure 26 shows the overall model system used by SHA and BMC, which includes both the MSTM maintained by SHA and BMC's regional travel demand model. Both models contain passenger travel demand models that are used to estimate personal travel by auto and other modes. The components of the freight model are shared between the SHA and BMC models; the approach to integration between the two models is discussed below. The NSCM comprises a firm synthesis model and a supply chain model. The NSCM simulates the transport of freight between supplier and buyer businesses in the United States and prioritizes movements that include Maryland. The model uses the output, a list of commodity shipments by mode, in two ways. First, in the MSTM, a model component connected to the NSCM converts the annual shipment flows to daily vehicle trip tables that can be assigned to the national and statewide networks in the MSTM along with trips tables from the passenger model. Second, the list of commodity shipments sorted by mode is used as an input to the FTTM in BMC's regional travel demand model. The FTTM simulates truck movements within the Baltimore region that deliver and pick up freight shipments at business establishments. The FTTM is a tour-based model and builds a set of truck tours. These tours include transfer points at which the shipment is handled before delivery/after pick up for shipments with a more complex supply chain (i.e., a warehouse, distribution center, or consolidation center) and the suppliers and buyer of shipments where those are within the model region. The shipment list from the NSCM is used as the demand input for the FTTM and describes the magnitude and location of delivery and pick-up activity in the region that must be connected by truck movements. The model generates trip lists by truck type and time of day so that the outputs from this model can be combined with the outputs from the CVTM and appropriate passenger vehicle trip tables for highway assignment. The CVTM simulates the remainder of the travel of light, medium, and heavy trucks for commercial service purposes (i.e., providing services and goods delivery to households and services to businesses). Like FTTM, the CVTM is a tour-based model, but demand is derived from the characteristics of the business establishments and households in the region and is not affected by the supply chain model. CVTM simulates truck and light-duty vehicle movements based on demand for services and goods from certain industries while FTTM simulates truck tours based on commodity flows. 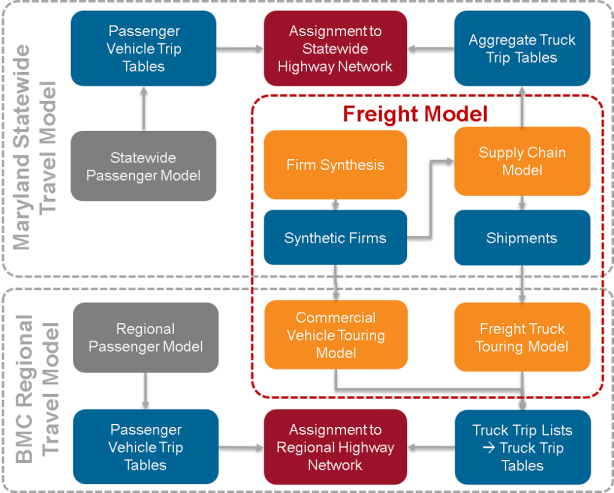
Figure 26. MSTM and BMC Model System.
The NSCM includes components that synthesize business locations, trading relationships between businesses, and the resulting commodity flows, distribution channel, shipment size, and mode and path choice for each shipment made annually. A flow chart of the NSCM is shown in Figure 27. The transport and logistics chain models produce a list of shipments that are ready for extraction for use in the regional truck-touring model. This output is also converted into number of vehicles and loads ready for modal assignment (in this case, assignment is done for all truck trips to the highway network, to produce outputs of trucks volumes on the highway network, including to and from transfer facilities). The components shown in the flow chart perform the following model steps as part of firm synthesis and supply chain modeling: Firm Synthesis
Supply Chain Model
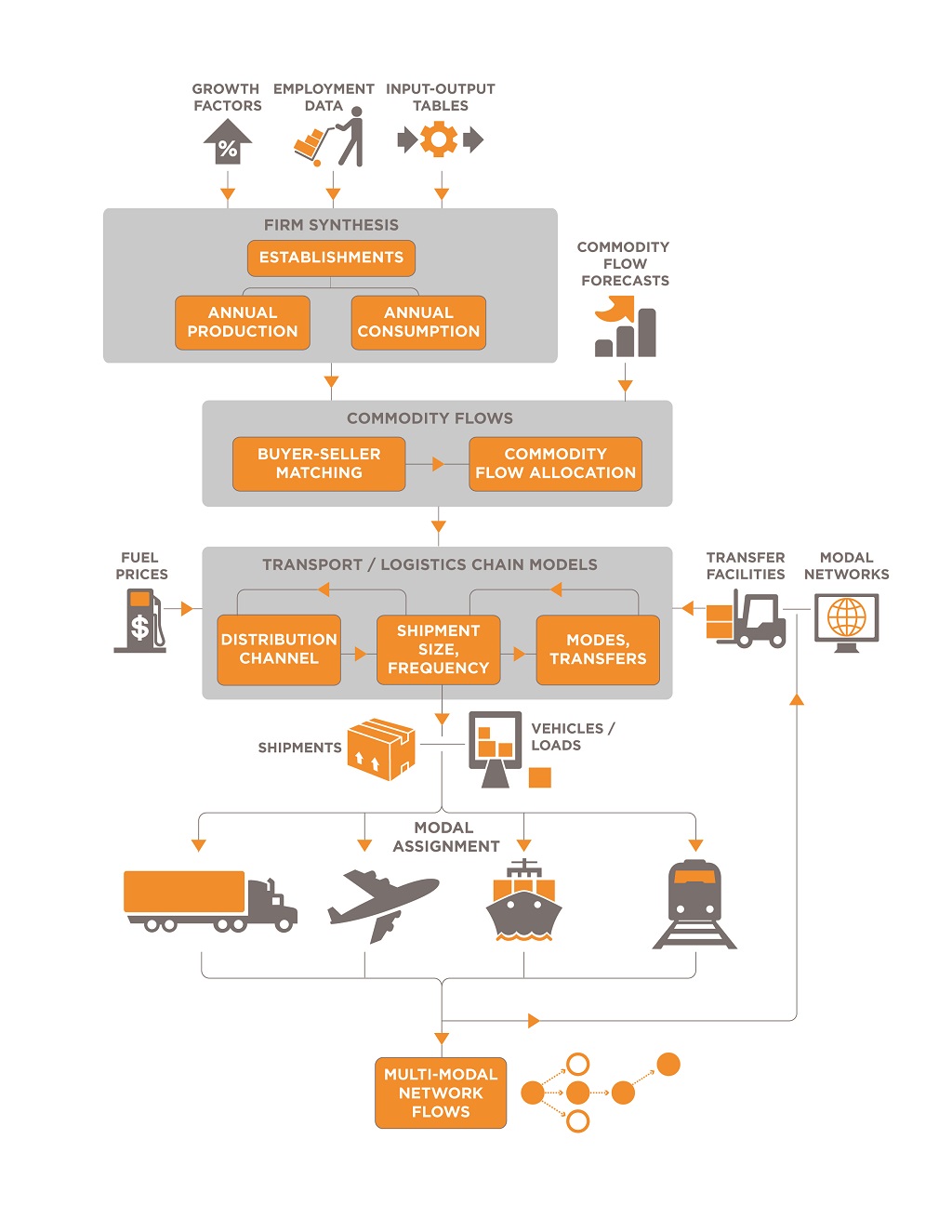
Figure 27. Components of the Supply Chain Model, SHA/BMC Model.
Market Segmentation (Industry, Commodity, Mode, Vehicle Type, Temporal, Activity Type)The SHA/BMC model system represents two major market segments for truck travel demand: freight movement and nonfreight commercial vehicle movement to provide services. The freight portion of the model—comprising the firm synthesis, supply chain model, and FTTM—contains several types of market segmentation depending on the unit of analysis of each model component. The firm synthesis model characterizes business establishments by location (TAZ), establishment size (eight employment categories ranging from 1–19 employees to over 5,000 employees) and industry (six-digit Census Bureau NAICS categories). The number, type, and size of business establishments is controlled at the TAZ level within Maryland using the regional employment forecast data, which are grouped into seven employment categories that are aggregations of NAICS categories (i.e., retail, office, industrial, education, health services, food service, and other services). The commodity production and consumption by business establishment uses the BEA's six-digit NAICS categories (which is slightly aggregated in comparison to the U.S. Census Bureau's NAICS categories used for the industrial classification of the business establishments). The supply chain model works with FAF commodity flow data and uses the 43 Standard Classification of Transported Goods categories for segmentation of shipment commodity. The distribution channel of the shipment flow through the supply chain is segmented into direct shipments, and those use one, two, or three transfers at distribution centers or intermodal transshipment locations. The supply chain model allocates shipments into size categories using a two-stage process, ultimately calibrating the distribution to the nine shipment-size categories, ranging from less than 50 pounds to more than 100,000 pounds used by the CFS. The shipments are allocated to one of four main modes (truck, rail, water, or air), with the intermodal paths being some combination of those modes (e.g., truck-rail-truck). The conversion to trip tables in the aggregate outputs from the supply chain model uses truck percentages for light, medium, and heavy trucks (FHWA class 2–3, 4–7, and 8–13, respectively). The trip tables are divided into four time-period-specific trip tables (AM peak, midday off-peak, PM peak, and nighttime off-peak) using fixed factors. The truck-touring model in the SHA/BMC model uses the same vehicle-type categories (light, medium, and heavy trucks) as the supply chain model's aggregate trip table outputs. The output trip roster from the truck-touring model has trip start and end times defined by minute of the day. These can be aggregated as needed into time period trip tables for static assignment. The stops that trucks make in the region are segmented into a series of different activity types. Scheduled stop activities (i.e., those where the truck is conducting its primary business) include delivery of a shipment, pick-up of a shipment, service activity, and meeting (with the latter two only relevant for nonfreight commercial vehicles). The model also adds intermediate stops for meals/breaks, vehicle service/refueling, and other purposes. Modeled Performance MeasuresThe outputs from the SHA/BMC freight model include databases of business establishments, shipments by mode, and truck trips. The truck trips are aggregated into zone-to-zone trips tables and assigned to both the statewide and regional highway networks to give medium and heavy truck class volumes, by link. The SHA/BMC freight model can produce the following performance measures from the model outputs:
Approach to ForecastingThe SHA/BMC freight model is integrated into both the Maryland Statewide Transportation Model (MSTM) and BMC's regional travel demand model. MSTM and the BMC's regional travel demand model are loosely integrated. SHA has assumed responsibility for the NSCM integrated within their MSTM and BMC has assumed responsibility for the FTTM and CVTM models integrated within their regional travel demand model. In this loose integration, the two parts of the model will operate independently. However, the outputs from the synthetic establishments located in the BMC region and the shipments traveling into, out of, and within the BMC region will be created by the NSCM within the MSTM. These outputs will then be provided as inputs to the urban freight modeling system (FTTM and CVTM) within the BMC regional travel demand model. For forecasting future scenarios, the firm synthesis model adjusts to match the input employment data at the TAZ level. The two agencies cooperate on employment forecasts and now use a consistent seven-category employment system, so the output business establishment database is appropriately adjusted for use in future years at both the statewide and regional level. The supply chain model's main future-year and alternative scenario inputs are commodity flow data and network inputs. By default, FAF forecasts are included as commodity flow data inputs, but the model user can adjust inputs to evaluate scenarios with alternative future commodity flows. The network inputs include forecasted changes in daily travel times and distances due to network changes (to highway, rail networks, and waterways) and to intermodal/transfer locations (e.g., rail yards, ports, airports, and truck terminals/distribution centers). The truck-touring models use the more detailed time-period-specific skims as the truck-touring models are sensitive to congested travel times by time period. As a result, forecasting in these models requires future-year scenario networks and the requirement of producing forecasted passenger trips to support joint assignment of passenger trips and truck trips. Types of Applications and ProceduresThe SHA/BMC freight model supports policy decision-making objectives, including project planning, corridor studies, and freight tolling. At the regional level, BMC staff use model simulation to support long-range plan development and federal transportation conformity determination. BMC staff use model outputs in regional transportation system performance measures of mobility, accessibility, equity, and environmental effects presented to committees. At the corridor level, performance measures of link level of service, travel speeds, and cost will be used at the project-planning level. These performance measures should be sensitive to existing and emerging transportation planning scenarios such as additional travel lanes, new interchanges, truck prohibitions, managed/electronic toll lanes, and freight generation scenarios such as port expansion or new intermodal transfer facilities. DataGeographic ScopeThe supply chain model, which is integrated with the MSTM, has a global geographic scope. At its broadest, it represents import and export movements to and from eight international zones. Domestic movements are represented to and from the rest of the Unites States, and the model design includes simplified transportation networks that cover the entire continental United States. The model uses the MSTM TAZ, system, which is more spatially detailed in portions of the states surrounding Maryland, and then more highly detailed within the State of Maryland. Figure 28 shows the North American extent of the model's zone system, and Figure 29 shows the State of Maryland and the halo of smaller zones around the State. The national transportation networks are connected to detailed transportation networks covering Maryland. The regional freight and CVTMs cover the BMC modeling region. Figure 30 shows the BMC modeling region and the TAZ boundaries within the region. 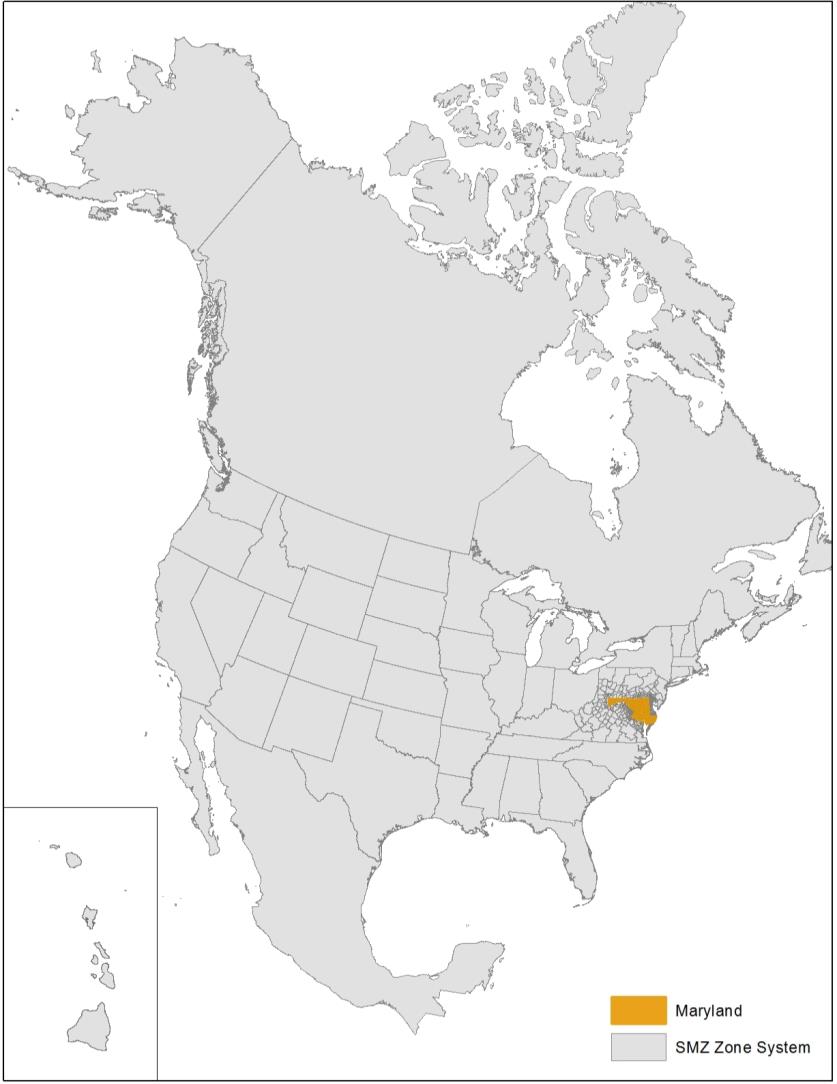
Figure 28. SHA/BMC Model Zone System, North American Extent of MSTM Zones.
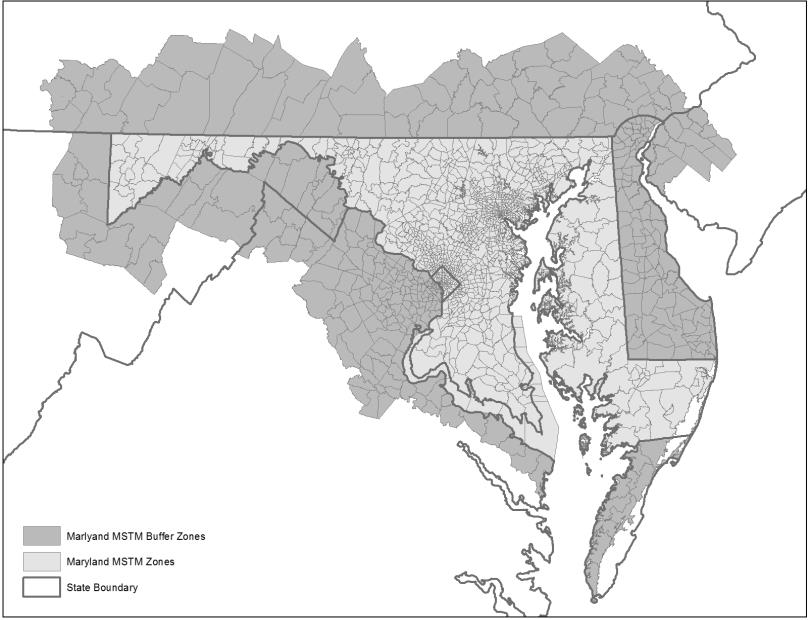
Figure 29. SHA/BMC Model Zone System, Maryland, and HALO Extent of MSTM Zones.
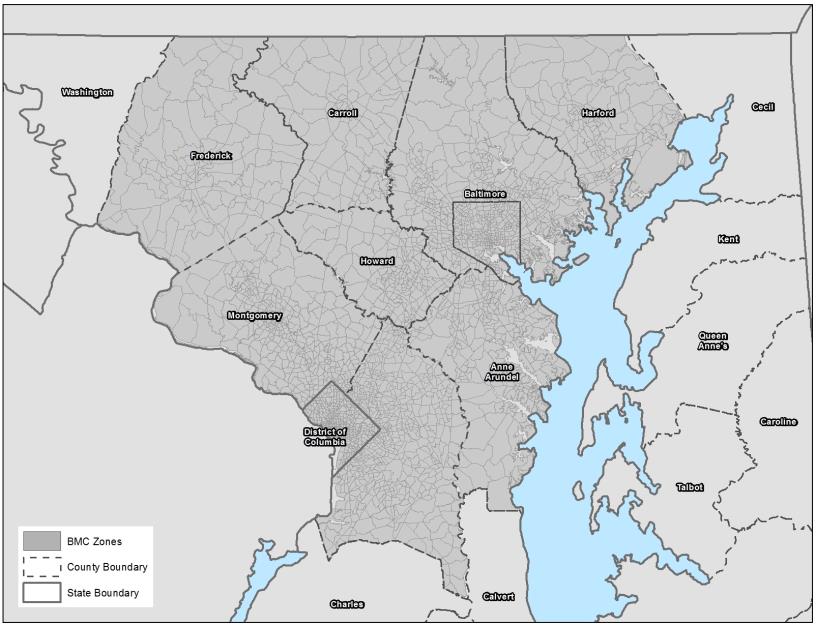
Figure 30. SHA/BMC Model Zone System, Extent of BMC Regional Zones.
Data InputsThe SHA/BMC models use the following main data sources as input:
Data Used for Estimating Model ParametersThe SHA/BMC model used the following main data source for estimating model parameters:
Data Used for Model Calibration and ValidationThe SHA/BMC model calibration and validation process relied on the following sources:
Data Desired, but not FoundSome of the desired—but unobtainable—data for use in the model included the following:
Detailed information about the model and the freight datasets is not yet available online. PORTLAND METROMethodologyMetro received a SHRP2 C20 grant and is currently developing a new behavior-based freight and commercial vehicle modeling system. The current model development effort will produce three major components:
Supply Chain Modeling NeedsThe new freight model will replace Metro's current trip-based truck model that utilizes fixed commodity flows with a joint supply chain freight model and truck-touring model designed to reflect decisions made by shippers, receivers, truck operators, terminal managers, and others. The model simulates movement of individual shipments throughout the supply chain, including both direct shipments, and those that traverse transshipment facilities. The model simulates movements of all freight shipments over one year and then simulates a representative sample of shipments on an average weekday in the truck-touring model. The objectives of the model and the project are as follows:
These objectives are identified by key participants in the project including Metro, Oregon Department of Transportation, the Ports of Portland and Vancouver, the Portland Freight Committee and several local agencies (e.g., City of Portland, Southwest Regional Transportation Commission, and Clackamas County). In applying for the grant to develop the model, Metro recognized the need for coordinated freight planning and freight's role as an economic engine for the region. This recognition facilitated the collection of freight data and the development of a new freight model. The freight model is being developed using the framework developed for FHWA and previously implemented as a demonstration project for CMAP. The model specification is being customized for the Portland metropolitan region and model parameters are being estimated or calibrated using data collected in a locally funded survey and passive data collection effort. The model uses simulated commodity flows between industrial sectors to estimate external flows into and out of the region for local producer and consumer entities, consistent with State and regional economic forecasts. Model Structure, Component Interactions, and SegmentationThe Metro freight model is based on a combined supply chain and tour-based framework developed with FHWA research funding and implemented in Chicago and Florida with RSG's rFreight" software. This framework comprises several steps that simulate the transport of freight between each supplier and buyer business in the United States. Figure 31 shows the supply chain processes and identifies major input and output data. 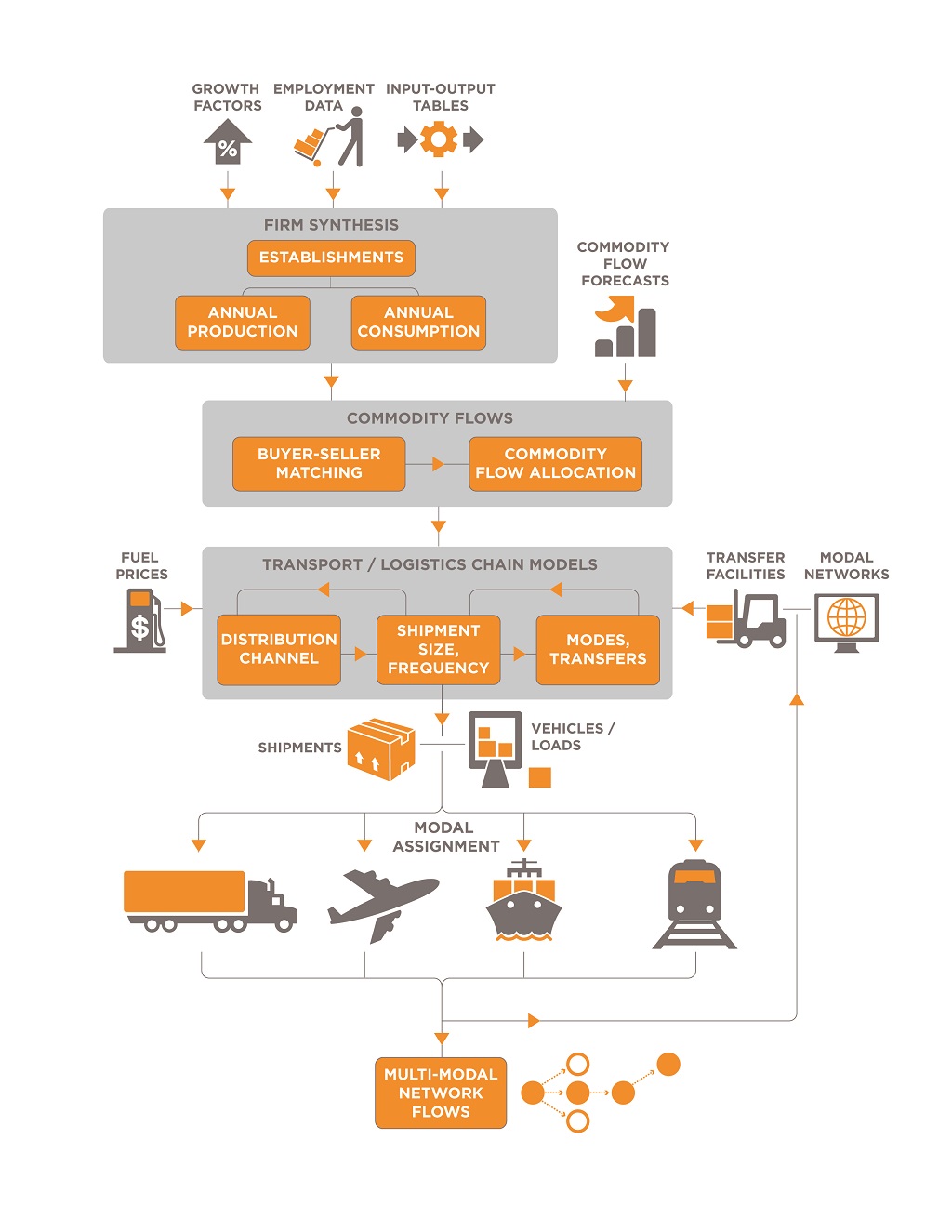
Figure 31. Metro Supply Chain Model Structure.
The modeling system sequence includes selection of business locations, trading relationships between businesses, and the resulting commodity flows, distribution channel, shipment size, and mode and path choices for each shipment made annually:
The supply chain model integrates with a regional truck-touring model, which is a sequence of models that takes shipments from their final transfer point to their final delivery point. The integrated modeling system connects the NSCMs with the regional truck-touring models. The final transfer point is the last point at which the shipment is handled before delivery (i.e., a warehouse, distribution center, or consolidation center for shipments with a more complex supply chain or the supplier for a direct shipment). It performs the same function in reverse for shipments at the pick-up end, where shipments are taken from the supplier to distances as far as the first transfer point. For shipments that include transfers, the tour-based truck model accounts for the arrangement of delivery and pick-up activity of shipments into truck tours. The Metro model also includes a separate CVTM to simulate the remaining nonfreight truck movements in the model region that are not captured by the FTTM. The two truck-touring models have been transferred from the new SHA/BMC freight model described in this synthesis and have been either estimated or calibrated using the local data collected during the Portland model project. The Metro freight model will be integrated with the passenger travel model and be part of the Metro travel demand modeling system. While the NSCM is not sensitive to local congested travel times within the Portland region—it is run using travel times and costs skimmed from a separate multimodal network—the two truck-touring models will be included within the Metro's travel demand model's feedback loops and use congested travel time skims as inputs. This means that the truck-touring patterns are sensitive to local congestion. Market Segmentation (Industry, Commodity, Mode, Vehicle Type, Temporal, Activity Type)The Metro freight model represents two major market segments in terms of demand for truck travel: freight movement and nonfreight commercial vehicle movement to provide services. The freight portion of the model—comprising firm synthesis, supply chain model, and FTTM—contains several different types of market segmentation depending on the unit of analysis of each model component. The firm synthesis model characterizes business establishments by location (TAZ), establishment size (eight employment categories ranging from 1–19 employees to over 5,000 employees) and industry (six-digit Census Bureau NAICS categories) and is controlled at the TAZ level within the Metro region using regional employment forecast data. This is grouped into 14 employment categories that are aggregations of NAICS categories. The commodity production and consumption by business establishment uses the BEA's six-digit NAICS categories, which is slightly aggregated in comparison to the U.S. Census Bureau's NAICS categories used for the industrial classification of the business establishments. The supply chain model works with FAF commodity flow data and uses the 43 SCTG categories for segmentation of shipment commodity. The distribution channel of the shipment flow through the supply chain is segmented into direct shipments using one, two, or three transfers at distribution centers or intermodal transshipment locations. The supply chain model allocates shipments into size categories using a two-stage process, ultimately calibrating the distribution to the nine shipment-size categories, ranging from less than 50 pounds to more than 100,000 pounds used by the CFS. The shipments are allocated to one of four main modes (truck, rail, water, or air), with the intermodal paths being some combination of those modes (e.g., truck-rail-truck). The truck-touring model uses light, medium, and heavy trucks (FHWA classes 2–3, 4–7, and 8–13, respectively) for vehicle-type categories. The output trip roster from the truck-touring model has trip start and end times defined by minute of the day. These can be aggregated into time period trip tables for static assignment. The stops that trucks make in the region are segmented into a series of different activity types. Scheduled stop activities (i.e., those where the truck is conducting its primary business) include delivery of a shipment, pick-up of a shipment, service activity, and meeting (with the latter two only relevant for nonfreight commercial vehicles). The model also adds intermediate stops for meals/breaks, vehicle service/refueling, and other purposes. Modeled Performance MeasuresThe outputs from the Metro freight model include databases of business establishments, shipments by mode, and truck trips. The model aggregates truck trips into zone-to-zone trips tables and assigns these to the regional highway network to produce medium and heavy truck class volumes sorted by link. The following performance measures can be derived from the model outputs:
Approach to ForecastingThe Metro freight model is being integrated into Metro's regional travel demand model. For forecasting future scenarios, the firm synthesis model adjusts to match the input employment data at the TAZ level. The supply chain model's main future-year and alternative scenario inputs are commodity flow data and network inputs. By default, FAF forecasts are included as commodity flow data inputs, but the model user can adjust these to evaluate scenarios with alternative future commodity flows. The network inputs include forecasted changes in daily travel times and distances due to network changes (to highway, rail networks, and waterways) and to intermodal/transfer locations (such as rail yards, ports, airports, and truck terminals/distribution centers). The truck-touring models use the more detailed time-period-specific skims because the truck-touring models are sensitive to congested travel times by time period. Thus, forecasting in these models requires future-year scenario networks for the Metro region and forecasted passenger trips to support joint assignment of passenger trips and truck trips. Types of Applications and ProceduresThe Metro freight model is multimodal and can evaluate the effect of infrastructure projects on system performance:
The Metro freight model can support the following types of transportation planning projects:
The Metro freight model can also help evaluate the effects of private sector decisions, such as just-in-time delivery, night deliveries, and adding or moving warehouse and distribution centers. DataGeographic ScopeThe Metro supply chain model has a global geographic scope. At its broadest, it represents import and export movements to and from international FAF zones. For the Metro model, given the proximity to Canada, the single Canadian FAF zone has been disaggregated into multiple zones based on groupings of provinces. Domestic movements are represented to and from the rest of the United States, and the model design includes simplified transportation networks that cover the entire continental United States. The model uses the FAF TAZ system and includes additional spatial detailed in Oregon and Idaho. The freight model uses the same TAZs as the current regional travel demand model within the four-county Metro region. Figure 32 shows the North American extent of the model's zone system, while Figure 33 highlights Oregon and Idaho. The regional freight and CVTMs cover the Metro modeling region. Figure 34 shows the Metro modeling region and the TAZ boundaries within the region. 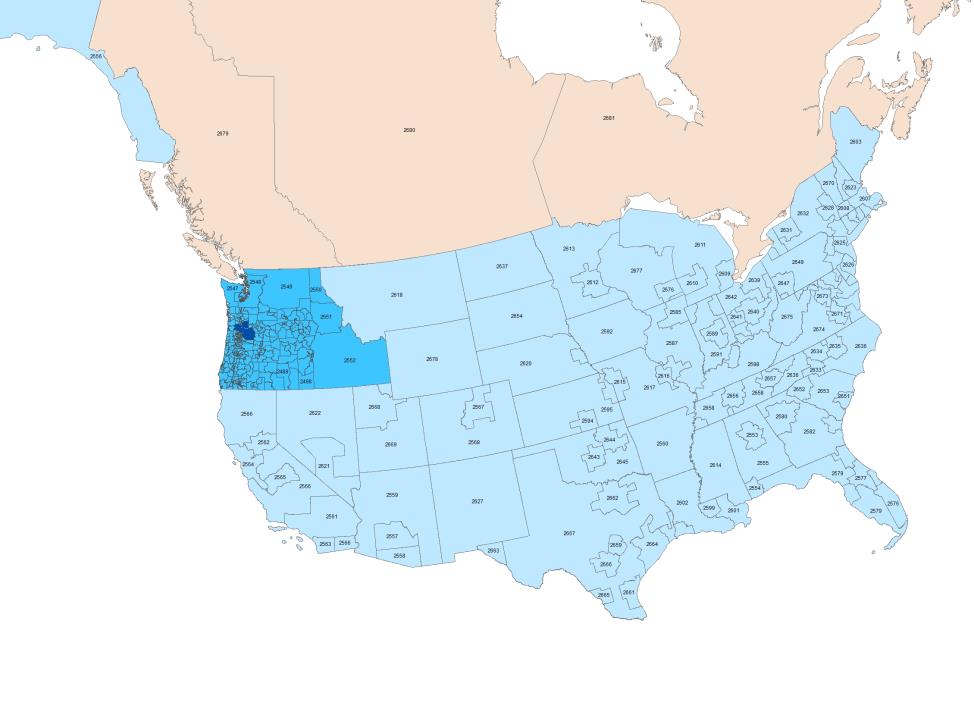
Figure 32. Metro Model Zone System, North American Extent.
Figure 33. Metro Model Zone System, Oregon and Surrounding States.
Figure 34. Metro Model Zone System, Metro Model Region.
Data InputsMetro has collected the following data to support model updates, calibration, and validation of their current truck model:
Metro collected data on shipping and truck travel behavior in the region for the development of the new Metro freight model. Metro used an establishment survey that collected both establishment-level data and truck driver diary data. The establishment survey employed both a traditional online survey and a smartphone app. Metro augmented the survey data by acquiring additional GPS truck movement data from INRIX, EROAD, and two businesses with truck fleets in the Portland region. The Metro freight model uses the following main data sources as input:
Data Used for Estimating Model ParametersThe Metro freight model used the following main data sources for estimating model parameters:
Data Used for Model Calibration and ValidationThe calibration and validation of the Metro freight model relied on the following sources:
Data Desired, but not FoundSome of the desired—but unobtainable—data for use in the model included the following:
SUMMARYThis summary of agency experiences focused on advanced freight forecasting models with elements of supply chain, including firm synthesis, procurement market models, transportation and logistics supply chain models, or truck movement models. This chapter reviewed and summarized seven in-use behavioral supply chain freight models. Table 9 summarizes the models reviewed.
1 Chicago region's long-range comprehensive plan (enumerated web address: http://www.cmap.illinois.gov/about/2040) [Return to Note 1] 2 Truck volume divided by total capacity. [Return to Note 2] 3 IMPLAN is a proprietary data source and includes data on employment, economic output for commodity categories, input-output data, and transportation spending, by industry. [Return to Note 3] 4 The VISUM Platform (enumerated web address: http://vision-traffic.ptvgroup.com/en-us/products/ptv-visum/) [Return to Note 4] 5 HERE Data (enumerated web address: https://here.com/en/products-services/map-content/here-map-data) [Return to Note 5] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
United States Department of Transportation - Federal Highway Administration |
||